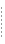

|
|
A data service gives you access to a structured view of a unit of information in the enterprise such as a customer, sales order, product, or service.
Collectively, a set of data services comprise the data integration layer in an IT environment. For additional information on data services see Unifying Information with Data Services in the BEA Aqualogic Data Services Platform Concepts Guide.
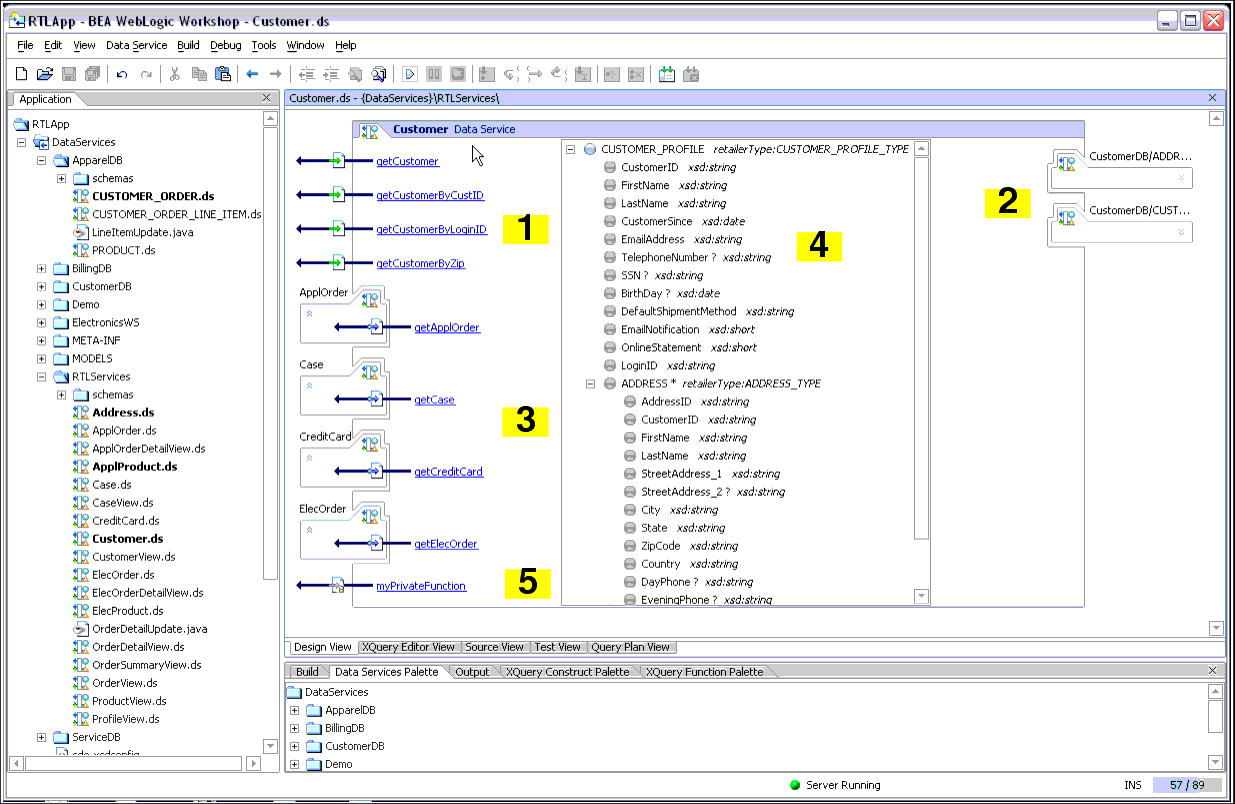
Design View presents the data service as a "integrated chip" or schematic representation (Figure 4-1) of all the query functions, underlying data sources, navigational relationships, and transformation logic needed to support returning results in a particular arrangement, the return type. For details see AquaLogic Data Services Platform Projects and Project Components.
A data service exists in a AquaLogic Data Services Platform-based project as a single XQuery file containing query functions and metadata support. For details see Working with XQuery Source and the AquaLogic Data Services Platform XQuery Developer's Guide.
For information on setting security and caching policies for functions and elements see Securing AquaLogic Data Services Platform Resources in the Administration Guide.
The following major topics are included in this chapter:
In modern enterprises there are increasingly two "data worlds": the traditional relational world of tables, columns, views, and stored procedures and the world of Web services and other forms of data that is accessed through the desktop or through various Web interfaces.
Increasingly, the cost of accessing and updating data across systems with fundamentally different architectures and purposes can rival the cost of setting up the services themselves.
A data service is similar to a conventional Web service in the following respects:
Of course a conventional Web service does not have a core XML data type that allows for easy manipulation of the shape of the return data. Another minor difference is that data services can access private functions contained in XQuery library files (.xfl files).
In concrete terms, a data service is a file that contains XML Query (XQuery) instructions for retrieving, aggregating, and transforming data.
There are two types of data services: physical and logical. Physical data services comprise both relational and service data. Logical data services are consumers of physical or other logical data services. The data access layer of the enterprise includes both logical and physical data services.
An important benefit of this approach is that in the case of a virtual data access layer such as the AquaLogic Data Services Platform provides there is no transfer or storage of data — other than for application-controlled caching. Instead data services simply expose interface calls to read functions that dynamically retrieve data from data sources. The retrieved data is then arranged based on the data service's XML type. Update logic is associated with each data service. In the case of relational data the update logic is automatic; otherwise custom update functions can be developed. See Handling Updates Through Data Services for details.
| Note: | Logical data services are built upon physical data services which in turn represent an underlying physical data source. Physical data service are created by importing metadata on a physical source and updated through synchronization. The schema file or XML type generated by this process should never be modified either in AquaLogic Data Services Platform or externally. Doing so risks invalidating your data service and dependent logical data services. (If you need to modify a data service based on a single source it is a simple matter to create a logical data service based on that one source.) |
Data services should be designed so as to present client applications with a sensible, uniform data access layer for obtaining and updating data.
The data service interface consists of several types of functions:
.xfl file) can contain private functions. Private functions can be accessed only by other functions within the data service or XFL. Such functions generally contain common processing logic, that is, operations for use in more than one function in the data service. (For functions designed to be shared across data services, see Creating and Working with XQuery Function Libraries.)In Source View you will notice that private functions are so identified in the pragma statement above the function.
| Note: | The single submit() function can be found in Source View. It is not represented in the Design View of the data service. |
Design View provides a means of visualizing the entire data service (see Figure 4-1). Each data service appears in WebLogic Workshop optionally bounded by panes that describe the application components, properties of selected Design View properties, and so forth. For details on AquaLogic Data Services Platform-based project components see AquaLogic Data Services Platform Projects and Project Components.
At the heart of each data service is its XML type. The XML type describes the shape of the document that will be returned when read functions are called either from this or a related navigation function. (For additional information see XML Types and Return Types.)
Table 4-2 details the functional components of the data service shown in Figure 4-1.
Read function and AquaLogic Data Services Platform procedures are typically developed through the XQuery Editor.
Read functions provide an API for the data service. In Figure 4-1 the getCustomer() function accepts a custID and returns data in the shape of the customer XML type. (See Modifying a Return Type).
|
||||
The data services that are used as immediate building blocks for the current data service are shown. Click on its chevron symbol
|
||||
Relationships that are both inferred (relational) or created are shown. Navigation functions return data in the shape of their native type. Clicking on the chevron symbol
Relationships can be created through the AquaLogic Data Services Platform modeler (see
Modeling Data Services) or directly in your data service using the relationship wizard (see Using the Relationship Wizard to Create Navigation Functions).
|
||||
The XML type is represented by an editable XML schema. The return type of read functions shown in the XQuery Editor (see
Working with the XQuery Editor) should match the data service XML type.
|
||||
| Note: | Multiple data services can depend on a single XML type. In such situations it is advantageous to design such data services as a group, so that they always should return the same XML type. |
A key product of AquaLogic Data Services Platform-based projects are data service query functions and return types, sometimes called target schemas. XML schemas are used to represent in hierarchical form physical and logical data and the shape of documents returned from AquaLogic Data Services Platform queries.
Return types can be thought of as the backbone of both data services and data models. Programmatically, return types are the "r" in for-let-where-return (flwr) queries.
Return types have the following main purposes:
For more information on specifying the XML type in a data service see Associating an XML Type.
The AquaLogic Data Services Platform modeler, data services, XQuery Editor, and Metadata Browser use XML type representations as follows:
For the versions of the XQuery and XML specifications implemented in AquaLogic Data Services Platform see the XQuery Developer's Guide.
| Note: | Data services supporting ADO.NET have additional, specific XML type requirements. For details see Supporting ADO.NET Clients in the Client Application Developer's Guide. |
Return types describes the structure or shape of data that a query produces when it is run. A return type can be thought of as an object of XML type.
| Note: | In order to maintain the integrity of AquaLogic Data Services Platform queries used by your application, it is important that the query return type match the XML type in the containing data service. Thus if you make changes in the return type, you should use the XQuery Editor's "Save and associate schema" command to make the data service's XML type consistent with query-level changes. Alternatively, create a new data service based on your return type. For details see Creating a Simple Data Service Function. |
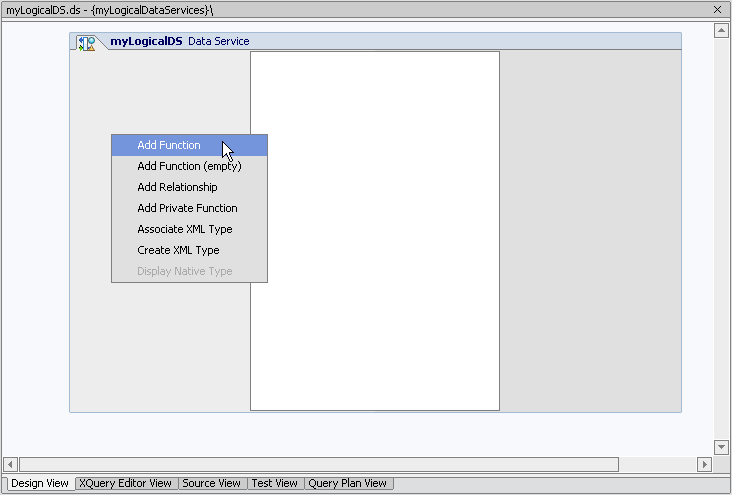
You can create a data service in several ways:
 New Data Service. Alternatively, right click on the project folder and choose New Data Service.
New Data Service. Alternatively, right click on the project folder and choose New Data Service.Data services always reside in the current AquaLogic Data Services Platform-based project. Once created, you can use the Data Service menu (or right-click) to develop your data service. Table 4-5 lists available right-click options and their usage.
Subsequent sections describe each of these commands in detail.
Read functions can be accessed by any calling application with the appropriate security credentials. When adding a read function to your data service, you can accept the default function name or edit it directly. Then, when you click on the name of your new function, you will be placed in the XQuery Editor. See Working with the XQuery Editor.
| Note: | It is important that function names in any given data service be unique even when their arity (number of parameters) does not match. This is because JDBC is not able to differentiate between functions of the same name. |
Data service procedures or side-effecting functions enable you to invoke external routines that do not necessarily return data. A common scenario would to use a procedure to invoke a Web service which in turn updates data. Another use of a procedure would be to invoke a relational stored procedure which in turn performs a database operation. The only thing returned in such a case might be a "success" message and that would only happen if the stored procedure was designed to report its status and the calling procedure was set up to handle such returned data.
Procedures are added to physical data services only, as part of the metadata import process. For details see Identifying AquaLogic Data Services Platform Procedures.
A private function is similar to a read function, but it is only available to other functions in your data service. You can change a private function to a read function through the Property Editor or by editing the Source View pragma.
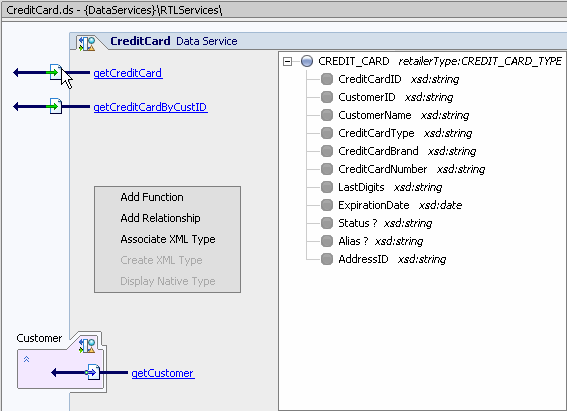
Relationships allow you to call out to another data service using an instance of your data service as a parameter. Data is returned in the shape of the related service. In this way you can populate your data services with a set of functions.
Two data services can be related by one or more relationships.
For example, CUSTOMER and ORDER might be related by a CUSTOMER-ORDER relationship that has three navigation functions in all:
cst:getAllOrders(CUSTOMER)ORDER*
cst:getOpenOrders(CUSTOMER)ORDER*
ord:getCustomer(ORDER)CUSTOMER
The first two functions are different ways of navigating the CUSTOMER-ORDER relationship from a customer to all or some of their orders. The third function is a way to navigate from an ORDER to the associated CUSTOMER.
In the most common case, a relationship will result in the availability of two navigation functions, one for moving through the relationship in one direction and one for moving in the other direction.
In the less common case of a unidirectional relationship, there will be only one navigation function.
In a data service the functional difference between a read function and a navigation function is the shape of the returned data. Here is a simple example:
In a read function if you have an OpenOrders data service with an XML type of:
<openOrders>
<custID>
<first_name>
<last_name>
<orderID>
..
</openOrders>
and pass it a customer ID such as 101 and an order ID such as LRP-111. The query result appears as:
<customerInfo>
<custID>101</custID>
<first_name>Jane</first_name>
<last_name>Smith</last_name>
<orderID>Smith</orderID>
..
</customerInfo>
However, if your data service has a navigation function associated with a table called TrackOrders, the query parameter can remain the same but data will be returned in the shape of the TrackOrders type, which looks like this:
<TrackOrders>
<custID>
<first_name>
<last_name>
<orderID>
<ship_date>
<weight>
<delivery_date>
...
</TrackOrders>
In a data service adding a relationship is a three-part process:
You can develop fully-functional binary navigation functions using the Relationship wizard.
The value of navigation functions is that client applications can call the function using complex parameters without having to know the internal structure of function, join conditions, and so forth. From the perspective of the data service creator, the internals of the function can be changed without affecting applications dependent on the ability to invoke the data service function.
When you choose to create a relationship through Design View or within a model diagram, the Relationship wizard is invoked. With the wizard you can set the following navigation function notations:
You can also identify parameters and specify where clauses.
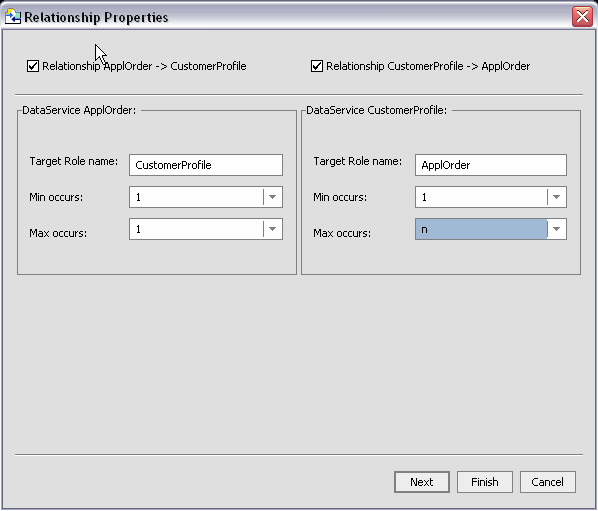
The first dialog of the Relationship wizard allows you to set role names, direction, and cardinality.
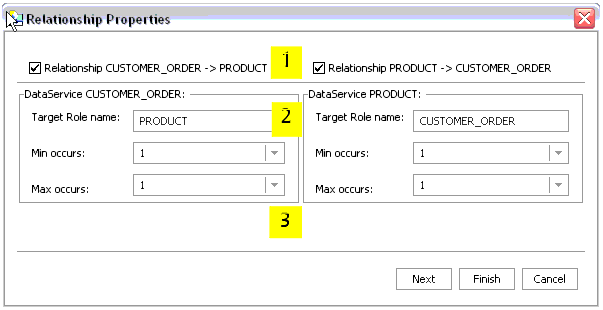
Table 4-8 provides details on the callouts shown in Figure 4-7.
Each end of a relationship can have a target role name. By default, the role name is the same as its adjacent data service. For example, the default role name for the ADDRESS data service is ADDRESS. You can change the role name in the Relationship wizard.
Role names can also be specified through the Property Editor associated with your data service or through a model diagram showing the relationship.
|
||||
Cardinality notations can be set for each side of the relationship. The default cardinality is 1-to-1 but this can be changed to any combination of <blank>, 0, 1, and n.
Cardinality can also be specified through the Property Editor associated with your data service or through a model diagram showing the relationship.
|
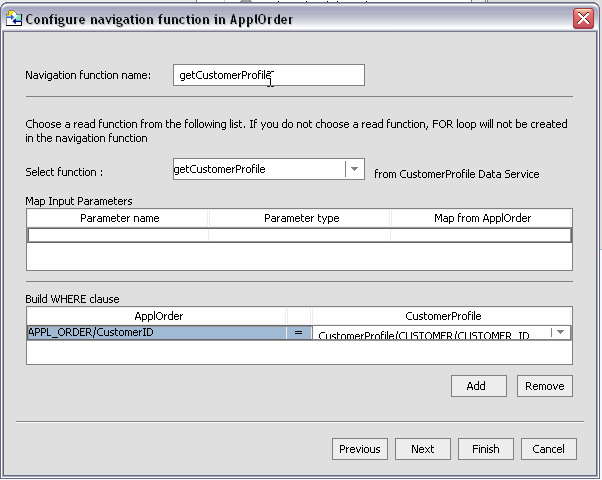
The second Relationship wizard dialog page allows you to set the navigation function name and other characteristics.
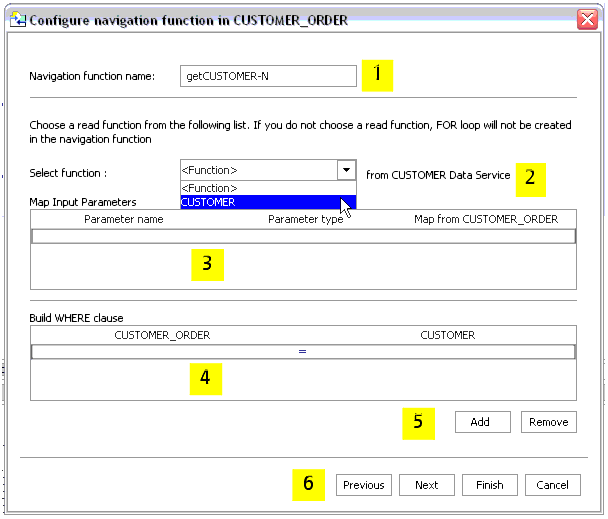
Table 4-10 provides details on callouts shown in Figure 4-9.
By default, the navigation function name is the name of the target data service with "get" prepended, as in "getCustomer". If a function of that name exists, numbers will be appended to the function name as in getCustomer1.
|
||||
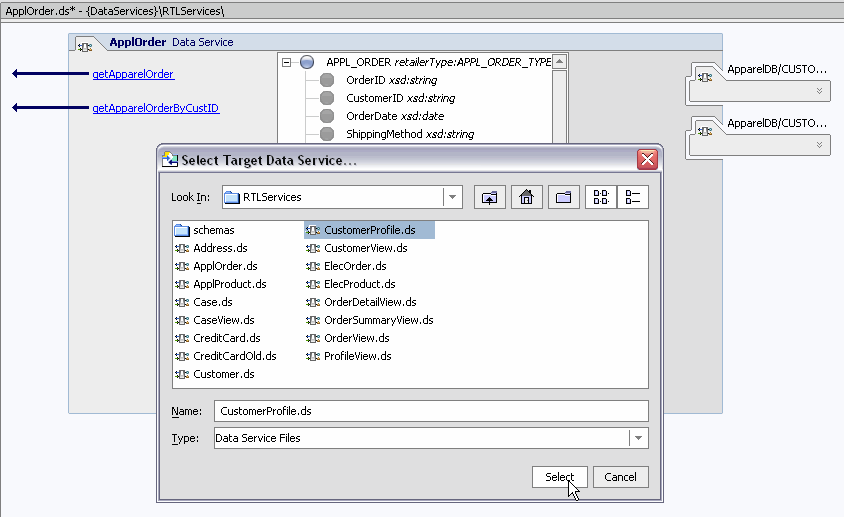
This section contains a small example showing how you can use the Relationship wizard to create fully-formed navigation functions. The goal is to create a navigation function that returns the first available address on file for a particular customer by supplying a customer ID.
The following steps use the RTLApp provided with AquaLogic Data Services Platform.
The relationship remains bidirectional, meaning that you can get customer profile information by supplying an address object and you get can address information using a customer profile object. However, the cardinality relationship notation of Customer Profile Address is 1-to-n, since a customer can have multiple orders.
The next stage for each navigation function is to:
In the case of the getCustomerProfile( ) navigation function:
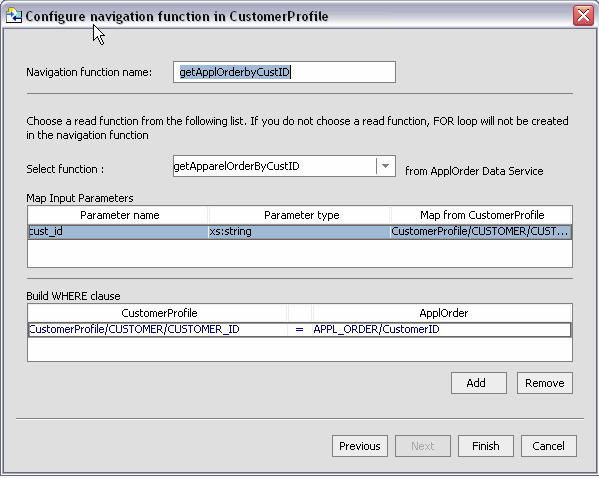
The apparel orders data service more typically contains multiple read functions. If you select getApparelOrdersByCustID(), then you will be able to map an element (cust_id) from the opposite data service.
Notice in Figure 4-14 that the where clause you defined for the first navigation function is pre-determined and shown in read-only format.
When you execute a navigation function in Test View, you can provide input in the form of a complex parameter such as would result from, for example, getting back a customer record. Alternatively, you could use the Test View template option to supply the appropriate parameter. See Using the XML Type to Identify Input Parameters.
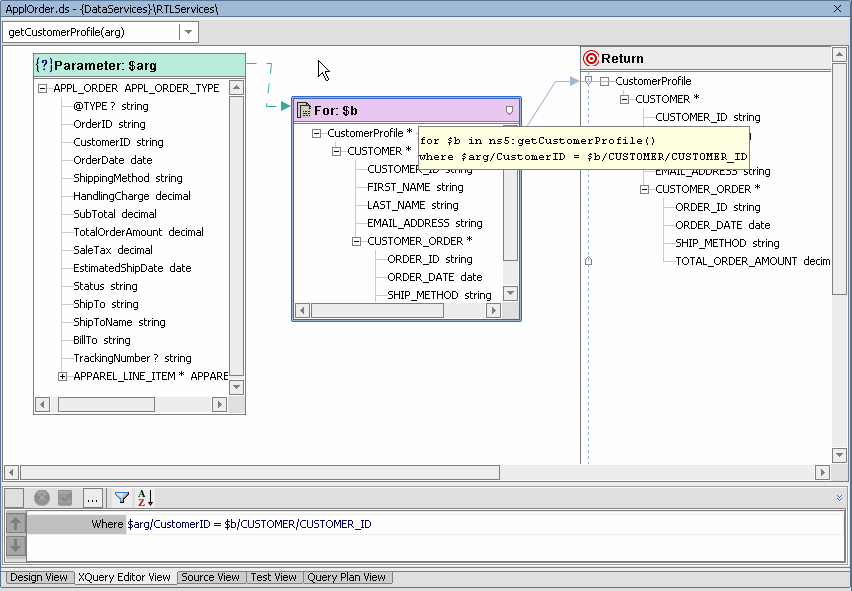
In data service Source View the navigation function is defined through a pragma and a function body. (For details see the AquaLogic Data Services Platform XQuery Developer's Guide).
For example, a navigation function named Payment() has a read function getPaymentList().
The navigation function appears as:
declare function ns1:getCustomer($arg as element(ns0:APPL_ORDER)) as element(ns15:PROFILE)* {
for $b in ns16:getCustomerByCustID($arg/CustomerID)
return $b
};
A key element in understanding this function is in the namespace ns15 which imports the schema that models the XML type, PAYMENTList.xsd. The namespace is defined as:
import schema namespace ns15="urn:retailerType" at
"ld:DataServices/RTLServices/schemas/Profile.xsd";
| Note: | If you modify a role name in the pragma of your data service, and that relationship exists in any model diagram, then you will need to similarly modify the role name in any model diagrams in which the relationship appears. Otherwise the relationship will become invalid. |
Read functions associated with data services return information in the shape of the data service's XML type.
| Note: | Logical data services are built upon physical data services which in turn represent an underlying physical data source. Physical data service are created by importing metadata on a physical source and updated through synchronization. The schema file or XML type generated by this process should never be modified either in AquaLogic Data Services Platform or externally. Doing so risks invalidating your data service and dependent logical data services. (If you need to modify a data service based on a single source it is a simple matter to create a logical data service based on that one source.) |
You can add or replace an XML type that has been associated with an data service using a browser. Your type must be located in the your application file structure.
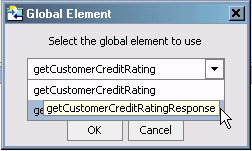
If the schema you select has more than one global element, a dialog allows you to choose the global element you want to use.
You can also edit an XML type. Several XML type right-click menu options are available (Table 4-17).
| WARNING: | Editing changes to an XML types in Design View immediately modify the schema file upon which the XML type is based. Such changes cannot be reversed through the Undo command. For this reason, XML types should be modified carefully, with adequate backup in case you need to revert to the original version. |
Another option, Enable Optimistic Locking, becomes available for elements in relational-based XML types under some conditions. See Enable/Disable Optimistic Locking.
Table 4-18 identifies how various right-click options apply to different XML type elements.
In some cases complex type components that appear in schemas will not appear in your XML type.
| Caution: | XML types are based on schemas which may be used by other data services. For this reason, XML types should be modified carefully, with adequate backup in case you need to revert to the original version. Similarly, all the functions in your data service should be written to return the XML type of your data service. |
In addition to the right-click menu described in Table 4-18, you can use the Go to source command to edit your schema file using WebLogic Workshop's assigned text editor.
You can choose to create an XML type for a new data service. Since your data service already has a name, you need only supply:
By default, the name of your data service is the same as the schema file name, the schema, and the target namespace.
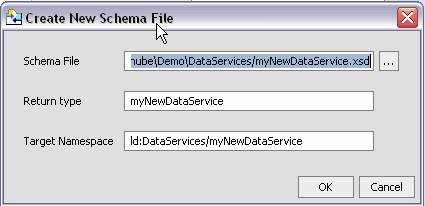
Once created, you can use the data services built-in schema editor to create your schema. Alternatively, you can create a schema in a program such as XMLSpy.
There are several important pre-deployment tasks you need to accomplish before you can make your data service available to client applications. This includes setting properties for your data service and it's functions.
You can use the Properties Editor (View Property Editor) to set or change key data service functionality including:
See Notable Design View Properties.
You can refactor data service functions insofar as they can be renamed or safely deleted. See Refactoring AquaLogic Data Services Platform Artifacts.
For most AquaLogic Data Services Platform artifacts you can quickly determine the artifacts usage through a right-click menu option. See Usages of Data Services Artifacts.
Each data service contains a set of properties that control its update characteristics.
| Note: | For information on decomposition functions, override classes, optimistic locking settings, and other SDO-related information see Handling Updates Through Data Services. |

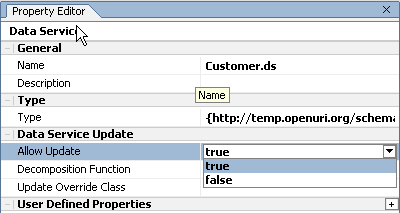
You can use the Allow Update option in the Property Editor to control whether calling applications can exercise update logic associated with your data service. This is especially important in regard to relational-based data services, since update logic is automatically available unless disabled.
Set the option to True to allow update; False to prevent updates.
In order to update non-relational sources that are associated with your data service you need to create an update override class. In addition, you may want to overwrite built-in update logic for relational sources to apply custom logic to the update process.
Before you can set the override class, you need to develop it. The steps involved are:
<javaUpdateExit className="nameOfYourJavaClass"/>
For information on developing an override class see Handling Updates Through Data Services.
| Note: | Each data service can have only one update override class. However, multiple data services can share the same update override class. |
The SDO update mechanism for relational data uses an optimistic locking policy to avoid change conflicts. With optimistic locking, the data source is not locked after the SDO client acquires the data. Later, when an updated is needed, the data in the source is compared to a copy of the data at a time when it was acquired. If there are discrepancies, the update is not committed.
Optimistic locking update policy is set for each data service. The following table lists optimistic locking update policy options.
For relational-based data service the Enable/Disable Optimistic Locking option becomes available for elements in its XML type when the optimistic locking property is set to Selected. (Optimistic locking policies are viewed and set through the Property Editor (Figure 4-22). For information on additional properties see Notable Design View Properties.
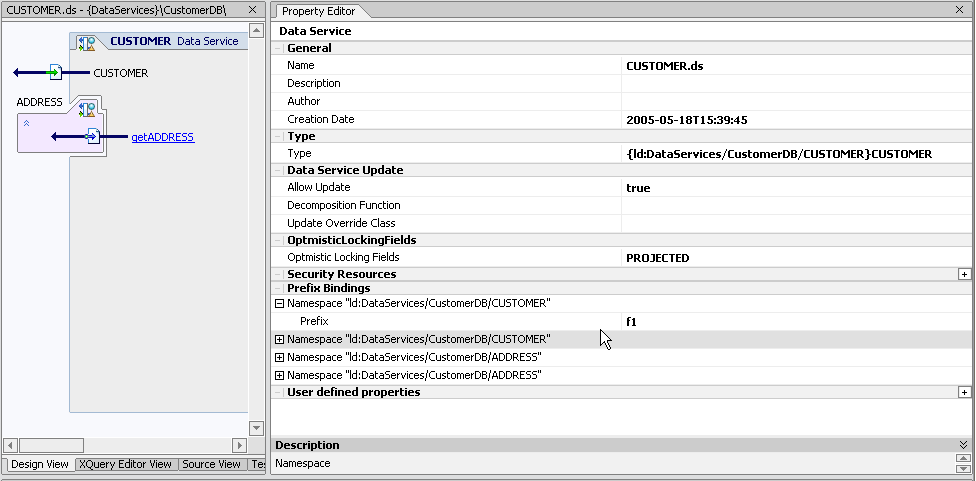
When active, the Selected Fields option allows you to validate optimistic locking logic prior to an update. Any number of fields can be selected through the right-click menu associated with the XML type. (If a complex element is selected, all its children are selected even though they are not so marked.)
When the Selected Fields option is picked, a right-click toggle option named Enable/Disable Optimistic Locking becomes available. Multiple elements can be selected.
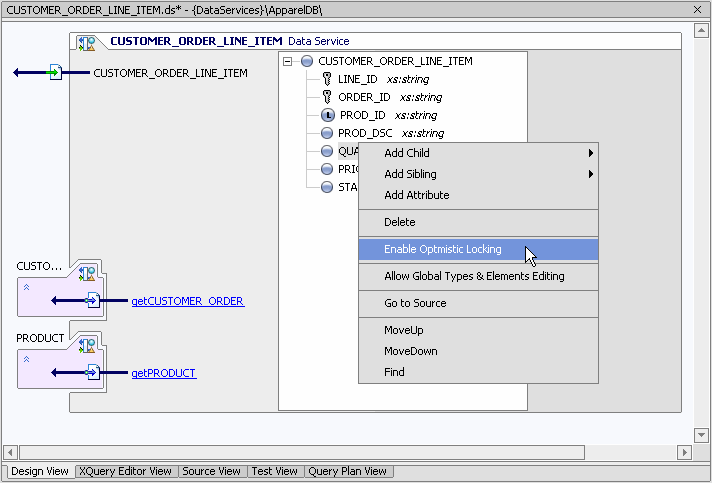
In Figure 4-23 two fields are selected, PRODUCT_ID and QUANTITY.
These choices are reflected in the Source View pragma.
<optimisticLockingFields>
<field name="PRODUCT_ID"/>
<field name="QUANTITY"/>
</optimisticLockingFields>
For details on handling change conflicts based on optimistic locking policies see Handling Updates Through Data Services.
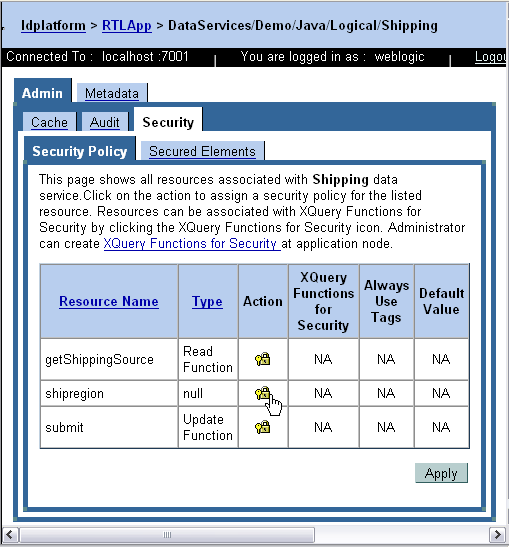
Security resource settings are created at the data service level and activated at through the AquaLogic Data Services Platform Console. The steps involved are:
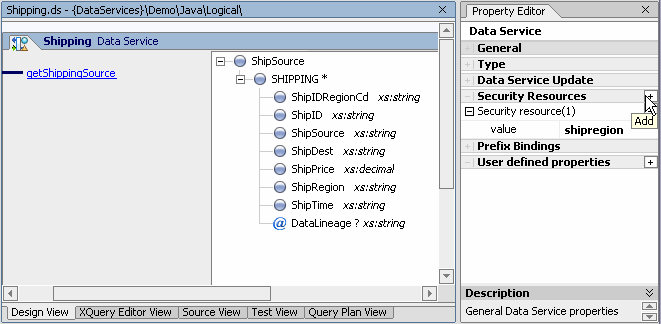
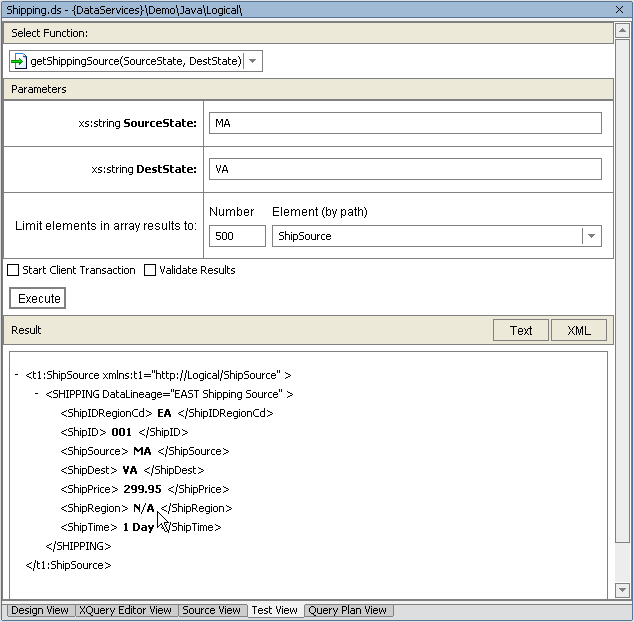
An easy way to understand security settings is to create an example using the Shipping data service found in the DataServices/Demo/Java/Logical folder of RTLApp.
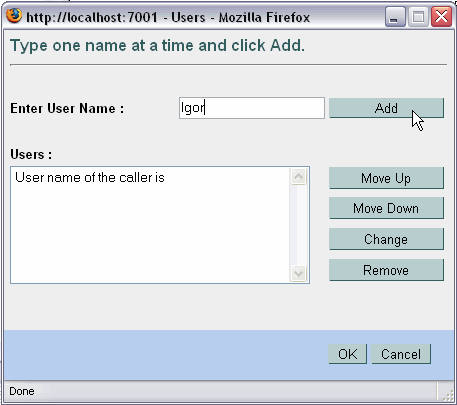
Goal. The goal is to restrict access for the East shipping region to the XML type's ShipRegion string to a particular traffic monitor named Igor.
The following section describe the steps involved.
This action add your new security resource (highlighted below) to the data service pragma in Source View.
(::pragma xds <x:xds targetType="ship:ShipSource" xmlns:ship="http://Logical/ShipSource" xmlns:x="urn:annotations.ld.bea.com">
<creationDate>2005-11-01T15:50:28</creationDate>
<userDefinedView/>
<secureResources>
<secureResource>shipregion</secureResource>
</secureResources>
</x:xds>
::)
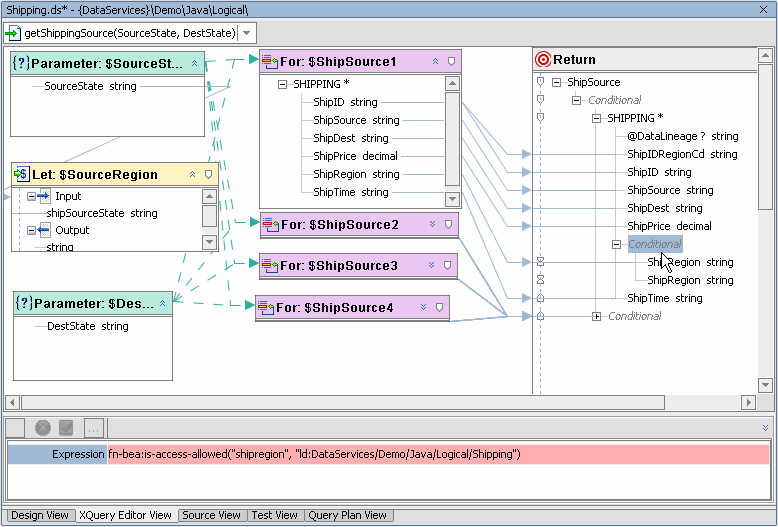
In this section you use the XQuery Editor to attach your newly created security resource to the EAST group, ShipRegion element.
| Note: | (For details on built-in BEA functions see the AquaLogic Data Services Platform XQuery Developer's Guide. For details on editing expressions see Transforming Data Using XQuery Functions.) |
In Source View your conditional is rendered as an XQuery if-else statement.
if (fn:upper-case($SourceRegion) eq 'EAST') then
(
for $ShipSource1 in ns10:getShipSource1()/SHIPPING
where $ShipSource1/ShipSource eq $SourceState
and $ShipSource1/ShipDest eq $DestState
return
<SHIPPING DataLineage?="{'EAST Shipping Source'}">
...
<ShipPrice>{fn:data($ShipSource1/ShipPrice)}</ShipPrice>
{
if (fn-bea:is-access-allowed("shipregion", "ld:DataServices/Demo/Java/Logical/Shipping")) then
<ShipRegion>{fn:data($ShipSource1/ShipRegion)}</ShipRegion>
else
<ShipRegion>{"N/A"}</ShipRegion>
}
<ShipTime>{fn:data($ShipSource1/ShipTime)}</ShipTime>
</SHIPPING>The next steps involve the AquaLogic Data Services Platform Console (see Securing Data Service Platform Resources in the AquaLogic Data Services Platform Administration Guide for complete details).
| Note: | Unless a secured resource has been marked as available to user weblogic or some group that user weblogic is a member of, it will not be available. |
Once security policies are established, they should be tested.
Examples.txt source file which is located in the Demo/Java/Logical folder.)For each function in your data service, the Allow Caching option can be set to True or False. If False, results from executing your query function cannot be cached. If True, results from earlier invocations of your function can be cached if cache for that function is enabled through the AquaLogic Data Services Platform Console. In other words, in order to cache a function it must be Enabled:True in its data service and also enabled through the AquaLogic Data Services Platform Console. For details on enabling cache for a function as well as setting the cache's TTL (time-to-live) see the AquaLogic Data Services Platform Administration Guide.
There are several things to keep in mind when considering whether to enable caching for a particular function:
To inspect or set the Allowed caching policy for a particular read function in your data service, click on the arrow to the left of the name of the function, then set its caching policy through the Properties Editor.
You need to build your application in order for cache policy changes effective.
| Note: | When a cache policy of Enabled:False is set for a function it cannot be overridden through the AquaLogic Data Services Platform Console. |
The following table, Table 4-31, identifies notable AquaLogic Data Services Platform Design View properties.
Identifies the function used for decomposition of the data service. In the case of physical data services the decomposition function is pre-defined by the source metadata.
|
|||||
This and the Sequence Object Name option appear for elements representing primary keys in relational-based physical data services.
|
|||||
Data sources modeled in XQuery can be exposed as a relational data source usable by SQL queries under the following conditions:
Such functions can be thought of as relational-compatible XQuery functions. Depending on their signature, such functions can be published for use as SQL tables, stored procedures, or database functions. The association between the function and the SQL object is defined at design time.
Types of artifacts publishable for SQL access include:
Table 4-32 shows the compatibility matrix between data service artifacts and SQL objects.
| Note: | See Data Services for detailed information on read and navigation functions and procedures and Creating and Working with XQuery Function Libraries for detailed information on XFL functions.) |
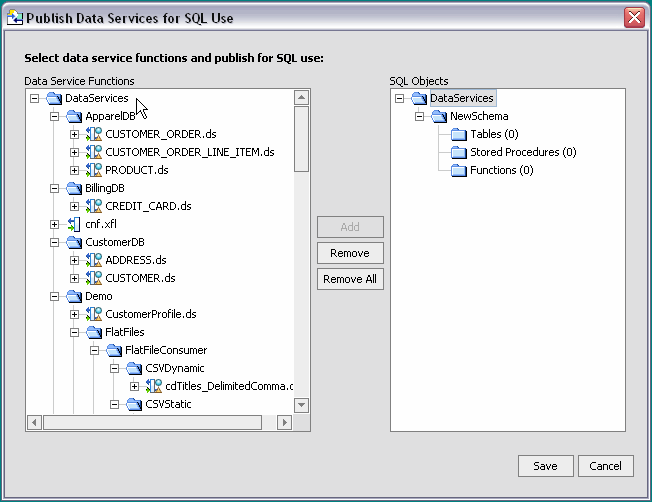
You can make your data service functions available for SQL use through a wizard (Figure 4-33) associated with your AquaLogic Data Services Platform-enabled project. Initially the wizard displays all data service functions in the project. Functions ineligible for publication are grayed out.
The right-side of the wizard is initially populated only by a renameable schema containing SQL object type names (Figure 4-33).
There are a number of ways that a function will be seen as ineligible for publication as a SQL object. For example:
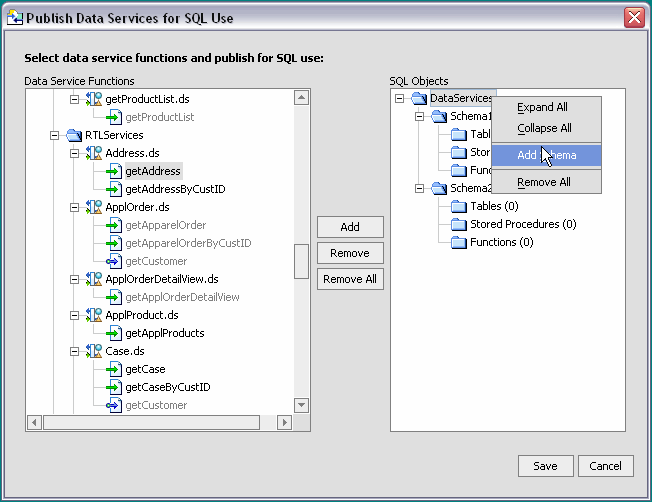
| Note: | The wizard supports the creation of any number of schemas under a catalog name that is the same as that of the AquaLogic Data Services Platform project. Using the right-click menu, you can rename, add, or delete schemas. For details see the Publishing Data Service Functions Example on page 4-48. |
The several steps involved in publishing data services for SQL use are described in this section.
| Note: | If you have previously created mappings between data service artifacts and SQL objects in the currently selected project, these mappings will appear. Otherwise you will see a wizard with no mappings to SQL objects (Figure 4-33). |
| Tip: | You can also drag-and-drop functions or folders to a selected SQL object type. |
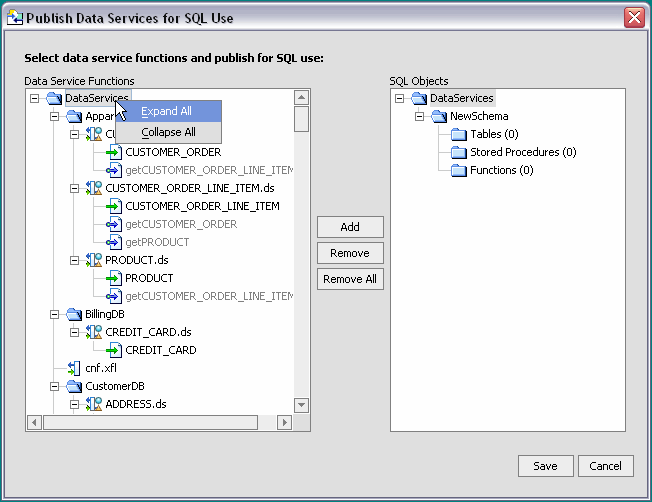
Notice in Figure 4-35 that some functions are grayed-out and unavailable for publication as SQL objects. If you attempt to map such a function, the alert dialog provides some detail on why the function cannot be mapped. In some cases, there may be several reasons why a function is not mapable; however, only one reason will be displayed.
| Note: | Why would you map a function that has no parameter as a stored procedure object? On the JDBC side different APIs are used for tables, stored procedures, and for functions. In some cases, it may be convenient to invoke a function without parameters as a stored procedure. |
| Note: | You can map the same data service function to multiple schemas. The wizard will, however, notify you when you map a function to multiple SQL object types. |
| Tip: | In the SQL objects area, you can also drag and drop published functions between various table, stored procedure, and function folders in the same or different schemas. The only requirement is that the function conform to publishing requirements. See Constraints on Publishing Data Service Objects to SQL for details. |
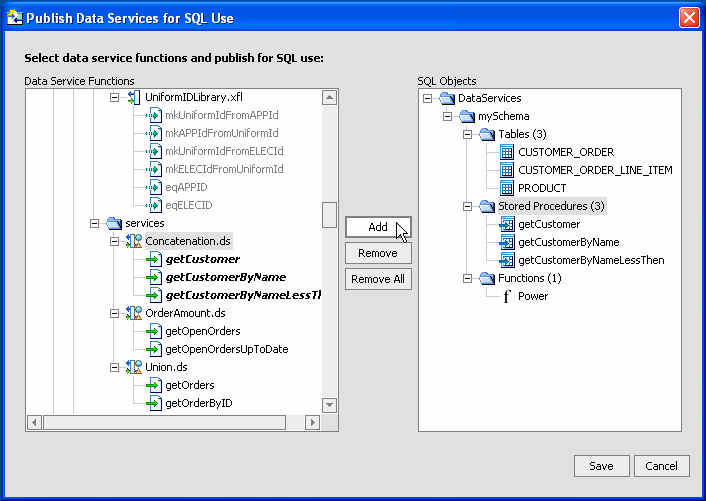
After you have mapped functions to SQL objects and attempted to save your virtual database catalog, you may see an alert dialog. This dialog provides a comprehensive summary of warnings and errors associated with your mappings, if any.
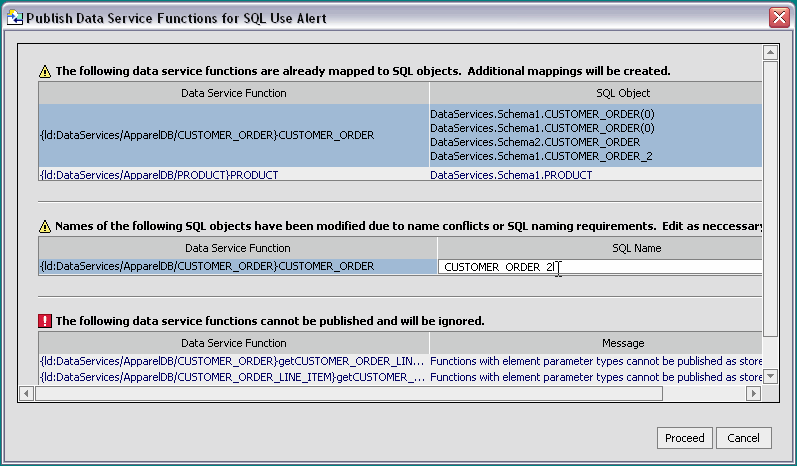
There are some semantic and structural constraints to publishing data service objects to SQL.
Semantic constraints include some general types of objects as private functions. Table 4-32 provides a matrix showing publishable AquaLogic Data Services Platform object types and their corresponding SQL object types.
There are also a number of structural constraints on publishing data service artifacts to SQL. Table 4-38 lists many of the more common limitations.
See How Non-Tabular Element Types Affect the Ability to Publish Functions as SQL Objects. Also applies to stored procedures.
|
|
declare function f($p as xs:string*) as xs:int |
|
declare function f() as element() |
|
See How Non-Tabular Element Types Affect the Ability to Publish Functions as SQL Objects. Also applies to tables.
|
|
The structure of a data service functions determines whether it can be mapped to an SQL object or not. For example, a parameterized function cannot be published as an SQL table since by definition SQL tables do not take parameters. Some structural constraints are practically self-evident; others are less obvious.
| Tip: | A quick way to determine if a particular function can be published to a particular type of SQL object is to drag the function to a SQL object table, stored procedure, or functions folder. Even if the function is grayed out — meaning that it cannot be published to any type of SQL object — an alert dialog (Figure 4-37) will appear explaining why the selected object cannot be published. |
For example, functions with non-tabular element types cannot be published as tables or stored procedures because XML output structure cannot be mapped to a normalized SQL table.
Underlying each data service is an XML type, or schema. Some XML types are readily mapped for JDBC use because they are — like SQL tables — two dimensional.
<CUSTOMER>
<FIRST_NAME>
<LAST_NAME>
<CUSTOMER_ID>
</CUSTOMER>
When published as SQL, the table structure corresponds to Table 4-39:
As long as the object mapper can reduce the structure of the XML document to rank-one, the mapping can occur. For example:
<CUSTOMER>
<FIRST_NAME>
<LAST_NAME>
<CUSTOMER_NUMBER>
<CUSTOMER_ORDER>
<ORDER_ID>
<C_ID>
<ORDER_DT>
</CUSTOMER_ORDER>
</CUSTOMER>
is publishable as a table in the following form as long as there is one or fewer customer orders associated with the customer:
If, however, the CUSTOMER_ORDER type is unbounded, meaning that it can represent more than one order associated with a single customer, the structure no longer corresponds to a well-formed relational table and the mapping is not allowed.
| Note: | In WebLogic Workshop an unbounded type is created and identified by zones in the return type zones. See Setting Zones in Your Return Type. The function in that example would initially not be mapable since multiple orders are associated with a single customer (master-detail in relational terms). However, if the zone associated with CUSTOMER_ORDER were removed, the function could be mapped and the resulting table would be similar to that shown in Table 4-40. |


|