
|
|
BEA Aqualogic Data Services Platform-enabled projects can be added to WebLogic Workshop in two ways:
The basic menus, common behavior, and look-and-feel associated with WebLogic Workshop apply to AquaLogic Data Services Platform. For detailed information on WebLogic Workshop see:
The following major topics are covered:
As noted above, you can create a WebLogic Workshop application that automatically includes a AquaLogic Data Services Platform project. Or you can add AquaLogic Data Services Platform projects to any BEA WebLogic application.
| Note: | It often makes sense to consolidate AquaLogic Data Services Platform queries into a WebLogic Workshop application dedicated to AquaLogic Data Services Platform development. Other applications can then access these queries through the DSP Mediator API or a AquaLogic Data Services Platform control. For complete details related to how client applications can access AquaLogic Data Services Platform functions and procedures see the Client Application Developer's Guide. |
To ascertain that AquaLogic Data Services Platform is available to your application or to determine the version that you are running, start your BEA WebLogic Server and access its Administration Console.
As an example, the WebLogic Server Console for the sample domain provided with BEA WebLogic can be accessed from:
http://localhost:7001/console
Navigate to the Console 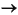 Versions page (Console being the top menu item) and find the version number and creation date for AquaLogic Data Services Platform.
Versions page (Console being the top menu item) and find the version number and creation date for AquaLogic Data Services Platform.
To create a AquaLogic Data Services Platform-based application select File New Application from WebLogic Workshop menu. When the dialog appears, select AquaLogic Data Services Platform Application (Figure 2-1).
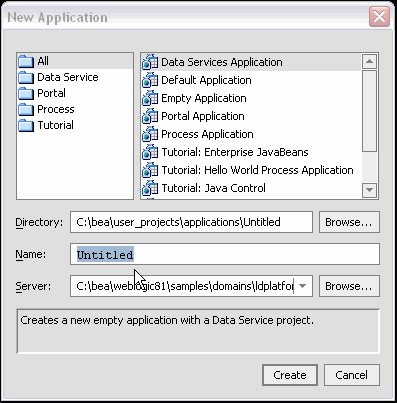
You probably will want to change the name of the application from Untitled to something else. Your new application automatically contains an initial AquaLogic Data Services Platform-based project.
You can save your application at any time using the File Save, Save As, or Save All commands. Save All saves any modified files in your application.
When you initially create a WebLogic Workshop application such as "myLD", a file called myLD.work is created in the root directory of your application. Invoking Workshop using this file also opens your application.
An application can contain any number of AquaLogic Data Services Platform or other types of WebLogic Workshop projects.
You can also add one or several AquaLogic Data Services Platform projects to any WebLogic Workshop application.
To do this select File New Project. When the project creation dialog appears, choose AquaLogic Data Services Platform Project.
When a new AquaLogic Data Services Platform application or project is created, a AquaLogic Data Services Platform project folder is also created. This becomes the root directory of your project (see Figure 2-3). Two Java archive (.jar) files are added to the application's Libraries folder including ld-server-app.jar and the mediator.jar. The latter file manages creation of Service Data Objects (SDOs), described in detail in the Client Application Developer's Guide.
Table 2-4 lists major AquaLogic Data Services Platform file types and their purposes.
Data services are contained in DS files and can be located anywhere in your application. Each data service file is an XQuery document.
|
|||
Data services typically are associated with XML types whose physical representation is an XML schema file. Schema files can be located anywhere in your application. Schemas automatically created by the Metadata Import wizard are placed in a
schemas project inside your application.
Schema files can be manually created or modified using any text editor. There is also a built-in schema editor in AquaLogic Data Services Platform Design View and in model diagrams containing the data service.
The XML type associated with a data service is also the return type of each function in your data service.The return type precisely describes the shape of the document to be returned by your query.
The return type can be modified through the XQuery Editor or directly in source. However, this generally should only be done in conjunction with the Save and Associate Schema command (see Creating a Simple Data Service Function for details).
|
|||
XQuery function libraries typically contain utility XQuery functions that can be used by application data services and in building data transformations. A typical example would be a routine for converting currencies based on daily exchange rate. Such transformational functions could be used by any data service in your application.
|
Other files which may appear in AquaLogic Data Services Platform projects include Java files containing custom update logic and SDO configuration files such as sdo.xsdconfig, which allows XMLBean technology to create SDOs rather than XMLBeans.
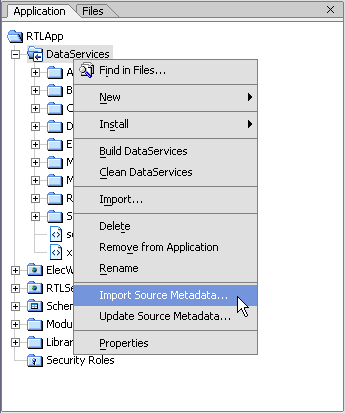
AquaLogic Data Services Platform adds several options to the standard WebLogic Workshop project right-click menu (Figure 2-5).
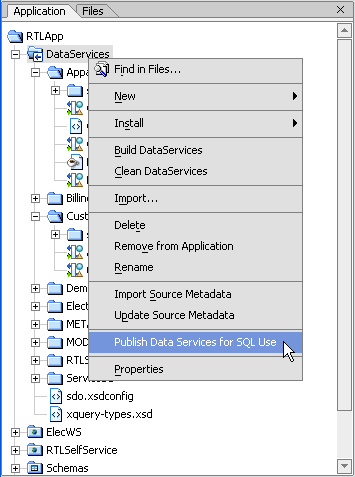
The following table describes AquaLogic Data Services Platform additions to the Project right-click menu.
AquaLogic Data Services Platform adds several options to the right-click menu associated with data services. (Figure 2-7).
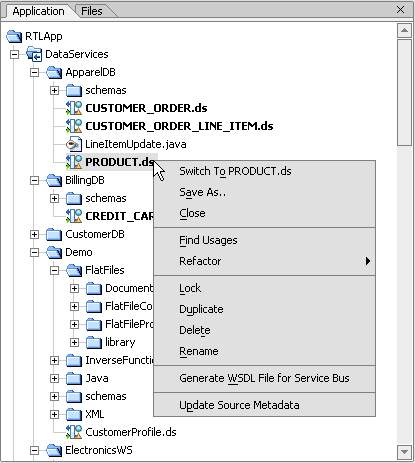
The following table describes AquaLogic Data Services Platform additions to the standard right-click menu options.
For information on determining where various AquaLogic Data Services Platform artifacts are used see Usages of Data Services Artifacts.
|
|
For information on data service refactoring operations see Refactoring AquaLogic Data Services Platform Artifacts.
|
|
WebLogic Workshop is fully described in on-line and printed documentation. A good place to start is:
Alternatively, WebLogic Workshop provides complete on-line help.
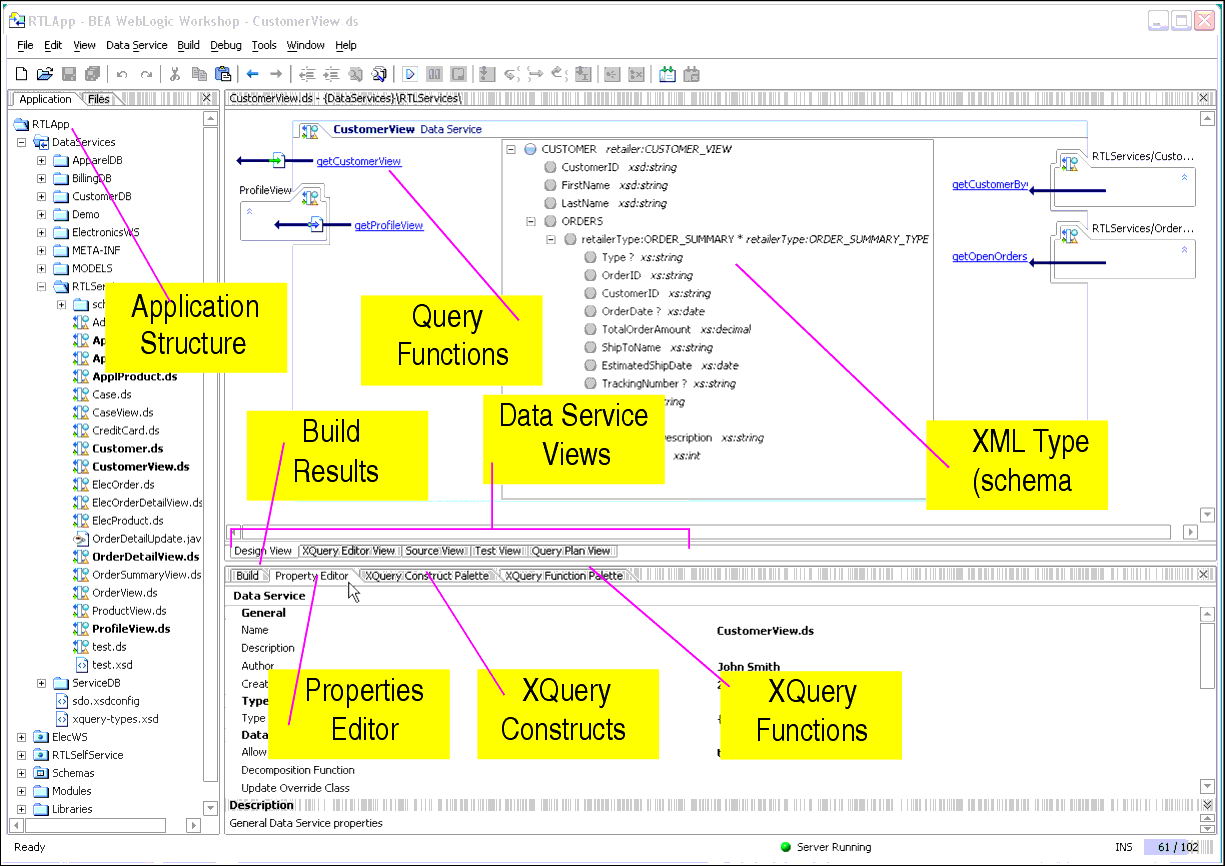
Table 2-10 briefly describes:
Table 2-11 describes the several WebLogic Workshop menu commands often used with AquaLogic Data Services Platform projects.
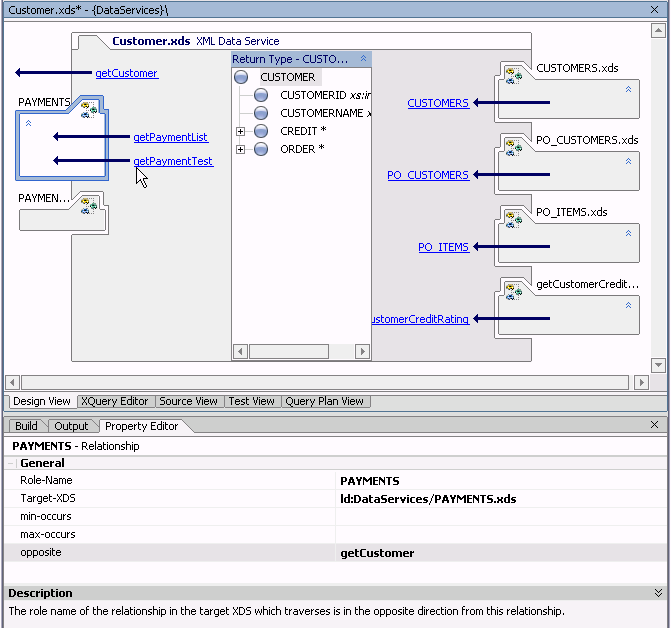
You can use the Property Editor to view details related to any WebLogic Workshop artifact (see Figure 2-12). For example, in Design View (see Design View) if you click on the general data service, the Property Editor provides details on that service. If you click on a relationship representation in your data service, property details on that relationship appear. In many cases, property settings are editable or configurable.
WebLogic Workshop provides a comprehensive file search facility with its Find in Files option, available from the Edit menu (Edit Find in Files).
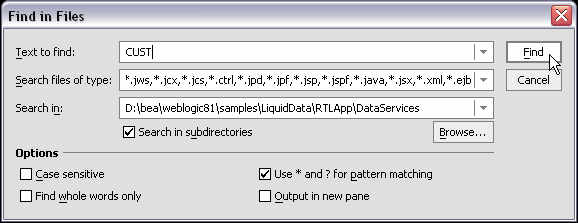
You can use Find in Files to search for references to any AquaLogic Data Services Platform artifacts such as particular data sources, use of functions, and so forth.
An AquaLogic Data Services Platform project adds menu items and views to the basic WebLogic Workshop environment to support the following functionality:
Data services are central to creating data models and physical and logical data views that can be used in AquaLogic Data Services Platform queries. The first step in creating a data service is to import metadata from physical data sources so that corresponding physical data services can be created.
For details related to importing and updating metadata into your AquaLogic Data Services Platform project see Obtaining Enterprise Metadata.
Through the data model interface that you can:
For details on developing and maintaining data models see Modeling Data Services.
Every data service provides a Design View, XQuery Editor View, Source View, Test View, and Query Plan View. Each data service is based around a single XQuery source file. And every data service has an associated XML type (XDS file).
Data services are composed of read and navigation functions and procedures. Read functions must return the XML type of the data service. Navigation functions, return the XML type of their native data service. Procedures, also known as side-effecting functions, need not return anything.
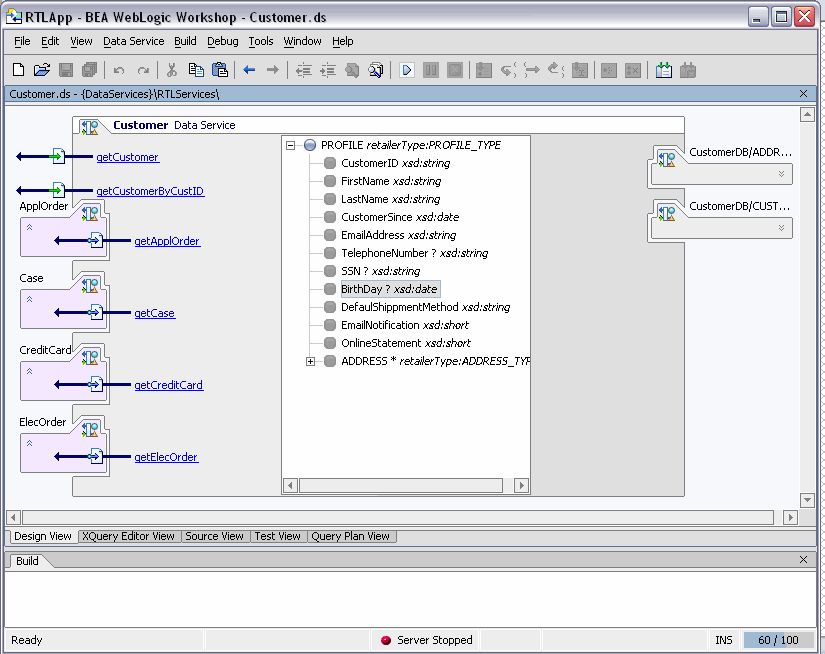
Design View is the central reference point of every data service. Through Design View that you can:
For details on developing and maintaining data services see Designing Data Services.
Through the XQuery Editor View you can develop query functions by projecting data service function elements, as well as transformations, to the function's return type.
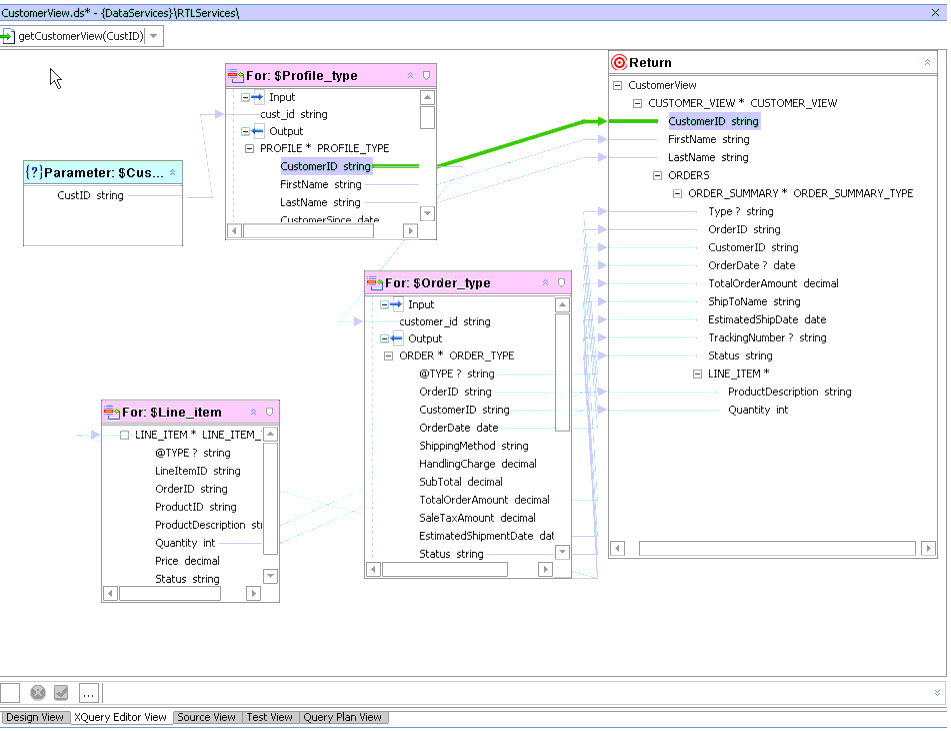
The graphical editor directly supports common constructs of the 1.0 XQuery standard. Several resources are available to help in the development and maintenance of business logic. These are all available from the WebLogic Workshop View or View Windows menu).
For details on developing queries using XQuery Editor View see Working with the XQuery Editor.
An XQuery function palette (Figure 2-18) is available that supports standard XQuery and BEA-specific functions. This function palette is also available from the Workshop View Windows menu.
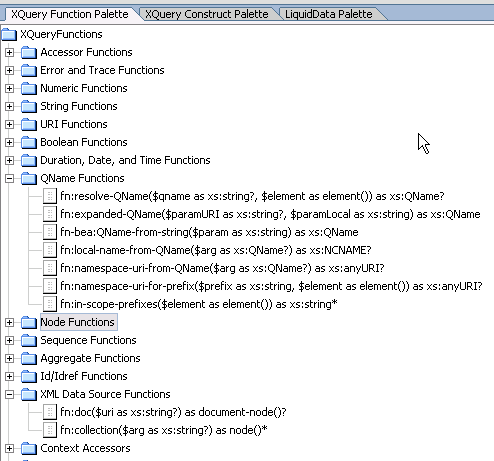
Like all Workshop panes, the XQuery Function Palette can be placed anywhere in the WebLogic Workshop window. Functions from this palette can be dragged into XQuery Editor View, as well as Source View.
AquaLogic Data Services Platform projects also have access to the XQuery Constructs palette (Figure 2-19). This palette supports creation of different types of XQuery statements in the XQuery Editor View or Source View. Many of the construct prototypes such as FLWGR, FGWOR, FWGR, and so forth are variations on the most common XQuery construct, FLWR (for-let-where-return).

For example, FLWGR adds the AquaLogic Data Services Platform extension Group By. The prototype is shown below in Source View.
for $var in ()
let $var2:=()
where (true)
group by () as $var3 with partitions $var as $var4
return
()
For details on Group By and other BEA XQuery extensions see the XQuery Developer's Guide.
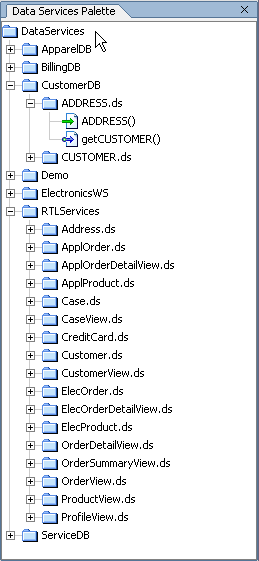
The Data Services Palette (Figure 2-20) is only available to AquaLogic Data Services Platform projects. It provides the AquaLogic Data Services Platform XQuery Editor with access to data service and XFL (XQuery function library) routines.
For details on using the XQuery Editor see Working with the XQuery Editor.
A schema editor for modifying XML types in model diagrams and data services, as well as return types in the XQuery Editor, is available. See Working with Logical Data Service XML Types. Most editor options are available from the right-click menu.
Right-click menu commands for return types differ slightly from those in the XML type editor. The reason is that you can use the XQuery Editor to create if-then-else constructs, zones, and cloned elements as a means of more exactly specifying the form your query result document should take. (See Modifying a Return Type.)
After you have developed a query you can run it using Test View. For details see Testing Query Functions and Viewing Query Plans.
If you are working in Source View you can easily add pre-built XQuery functions and constructs to your source, as well as make other editing changes to your data service. For additional details see Working with XQuery Source.
You can review the query plan developed by AquaLogic Data Services Platform for a particular function in order to verify the generated SQL or look for opportunities to improve performance. See Using Query Plan View.
A query plan viewer utility is available from the Start menu of a AquaLogic Data Services Platform-enable WebLogic Workshop application:
start All Programs BEA WebLogic Platform 8.1 BEA AquaLogic Data Services Platform 2.5Query Plan Viewer
Although this utility can be used while developing data services, it is more typically used by client application developers. Documentation for the utility can be found in the Using SQL to Access Data Services chapter of the Client Application Developer's Guide.
It is often convenient to determine which AquaLogic Data Services Platform artifacts are in use by which other artifacts. For example, before making changes in an XML type it is important to determine what other data services might be impacted. Of course you can do this through the Metadata Browser, described in the "Viewing Metadata" chapter of the AquaLogic Data Services Platform Administration Guide. However, it is often more convenient to do this in the context of the WebLogic Workshop navigation pane or the AquaLogic Data Services Platform Design View.
For example, in the RTLApp, right-clicking on a data service shows a number of options including Find Usages (Figure 2-22).
When you pick this option, usages of the artifact are displayed, as shown in Figure 2-23.
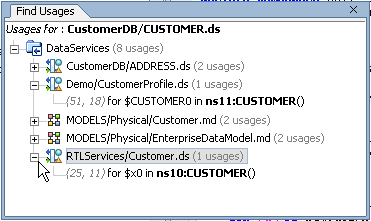
You can find the usages of the following types of AquaLogic Data Services Platform artifacts:
When you save a AquaLogic Data Services Platform application its JAR libraries files are bound to that application. If you subsequently migrate to a newer version of AquaLogic Data Services Platform, you also need to upgrade your application to the latest library files. For details see the AquaLogic Data Services Platform Installation Guide.
AquaLogic Data Services Platform attempts to rebuild your application as necessary. However, there are times when you will need to initiate a build directly.
Table 2-24 describes relevant Build menu options and their uses.
You need to rebuild your project whenever you delete a file from a AquaLogic Data Services Platform-based project. Rebuilds can occur on a project or at the application level. Generally speaking, there is no need to rebuild your entire application unless you have made changes to multiple projects.
Rebuild your project (or application) in two steps:
| Note: | If you try to run a function in Test View and it fails unexpectedly, it is often curative to clean, then rebuild your application before attempting to run your query again. |
If your application is already deployed, it will be automatically redeployed whenever you rebuild it. Under some conditions you may want to undeploy your application first. Table 2-25 describes relevant deployment menu options available when you click on your application folder in the Application pane.
|
|||
For additional information on deploying WebLogic Workshop applications see:
After you have created and tested your application's query functions, you need to make them available to client applications. The SDO mediator API is the primary means of providing access to your updateable functions.
| Note: | For details on SDO programming and accessing data in Java clients through the mediator API see Data Programming Model and Update Framework in the Client Application Developer's Guide. |
One way to create the SDO mediator client Java archive (.jar) file is through the right-click menu option Build SDO Mediator Client. This is only available from the root folder of your application.
When successful, your SDO mediator client will be created in the root directory of your application. The file will be named as:
<name_of_your_application>-ld-client.jar
The SDO mediator JAR file will also be automatically added to your application's Libraries folder.
| Note: | Insure that all of your projects are up-to-date and built before creating your SDO mediator JAR file. See also Building, Deploying, and Updating Applications on page 2-24. |
You can also create the SDO mediator client JAR file through the command line using ant scripts.
If you already have an EAR file you can use the script:
ant -f $WL_HOME/liquiddata/bin/ld_clientapi.xml
-Darchive=</your_path/name_of_your_application>.ear>
in which case the name of your JAR file will be taken from the EAR file:
<name_of_your_application>-ld-client.jarIt will be created in the same directory as the EAR file.
You can generate an SDO mediator client JAR file (without needing an EAR file) by simply specifying an application directory:
ant -f $WL_HOME/liquiddata/bin/ld_clientapi.xml
-Dapproot=</your_path/name_of_your_application>/root>
This approach will use the directory name of the application root to compute the JAR file name; in the above case the name would be root-ld-client.jar. If that's not what is wanted, you could specify:
-Dsdojarname=<MyApp-ld-client.jar>
to override this. Either way the JAR file will be generated in the application root directory.
For either case you could specify the additional ant parameter:
-Doutdir=</path/to/dir>
to generate the JAR file to a specific directory location.
-Dtmpdir=</path/to/tmp>
to specify an alternate directory for temporary files, including the generated .java code.
The default tmp file location is specified by the Java system property:
java.io.tmpdir
In any case, when building from the command line, the SDO mediator.jar file will not be added to your application's Libraries folder (shown in Figure 2-2).
There are times when you will want to move, rename, or delete artifacts in your AquaLogic Data Services Platform projects. A typical example: your application is first developed with test data, so as to not expose confidential information to unauthorized individuals. Then, once developed, your application is ready for deployment with the actual, secured data sources. You can use refactoring to greatly simplify the renaming, deleting, or relocating of AquaLogic Data Services Platform components.
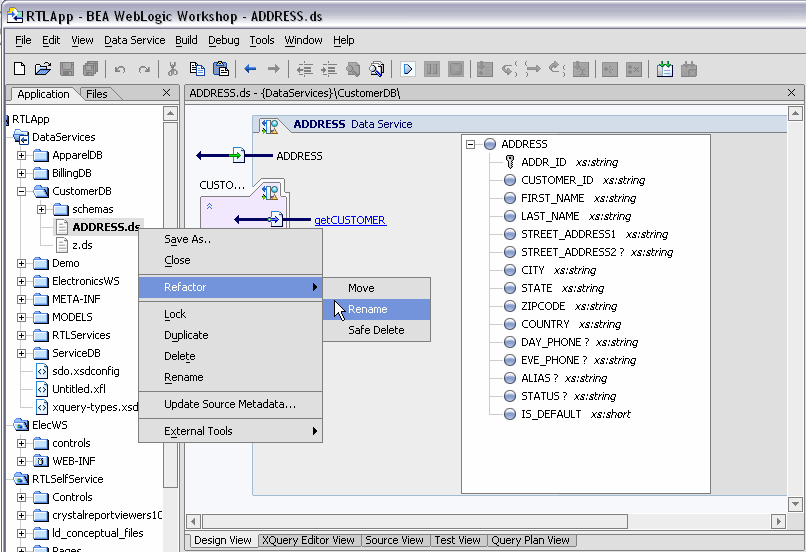
Without refactoring, changes you make to artifact names can easily result in invalid references. For example, renaming a data service file automatically invalids any relationship functions in other data services that refer to that file. The alternative to refactoring is to manually find all usages of a given artifact and make manual edits to data service source; this can be quite tedious and error-prone, particular as projects grow.
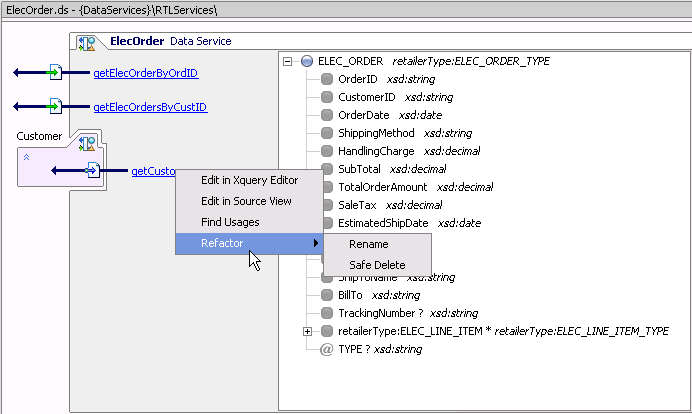
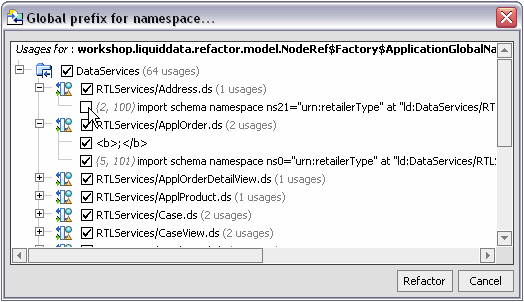
When you use the Refactor option you initially see the effect your refactoring change will have on impacted application artifacts (Figure 2-27). A checkbox allows you to exempt any artifact from the refactoring operation.
| Note: | Care should be taken when deselecting elements recommended for refactoring. Without additional manual changes to the underlying source you likely will no longer be able to build or deploy your application. |
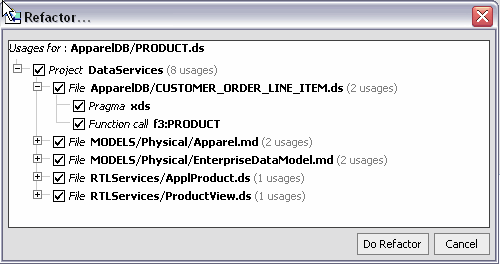
Table 2-28 describes artifacts subject to refactoring and their options.
Move, rename, and add/remove parameter operations are typically accomplished without adverse consequence. Delete operations, however, can adversely affect your project. For this reason the usages of the artifact you have identified for deletion are shown (see Figure 2-29). From this information you can easily determine the trade-offs between the automation of the refactoring operation and its consequences, which may require additional manual actions on your part.
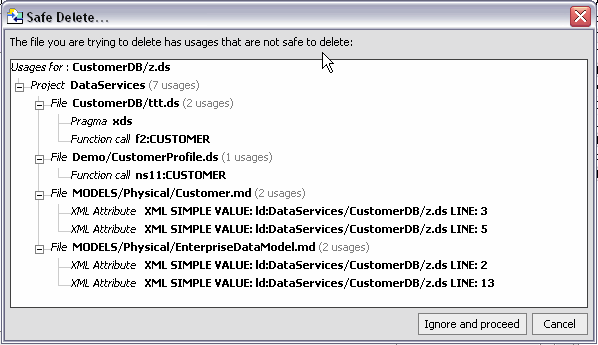
Access to refactor options depends on the artifact:
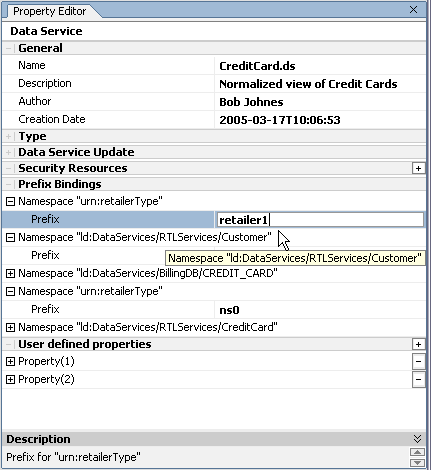
You can refactor a namespace or external schema prefix simply by changing its prefix name (binding) in the Property Editor (Figure 2-30).
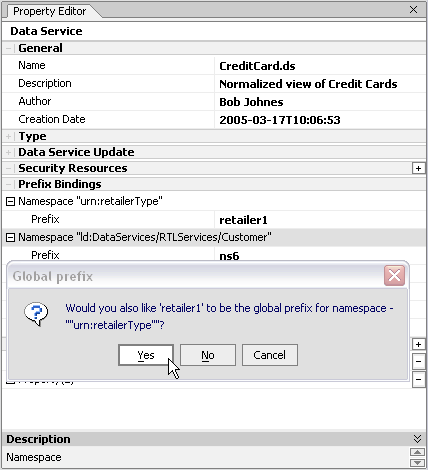
When you change a prefix binding you are also given the option of making the change throughout your project (globally).
If you choose this option (see anywhere the URI (urn:retailerType) appears in your project, the prefix will become "retailer1".
| Caution: | Although you can deselect any artifact that you do not want to be included in a refactor operation, doing so will invalidate that artifact and any files dependent on that artifact. For this reason selective deselection of artifacts scheduled for refactoring should generally not be employed. |
| Note: | In the case of namespace prefixes, names should be changed (or not) based on readability or consistency issues. Neither a local or a global change will adversely affect your code. |
It is useful to understand the various potential effects of a refactoring operation. In Table 2-34 each type of refactoring operation is described in terms of its potential impact on related artifacts.
XQuery function libraries (XFLs) contain functions that can be used by any data service or any other XFL in your application. Such libraries provide for:
Functions in XFL files cannot be directly invoked by data service clients. Instead, they are used by other data services. XFL functions provide user-defined routines that can be shared across a set of executable artifacts.
An XQuery function library (.xfl file) is ideal for creating sharable transformation, security, and other types of functions.
The first three types of files contain functions bound to an instance of a certain type of physical source (that is relational, WSDL, or class file). User-defined XQuery functions provide you with the ability to share common functions across all the data services in your project. External database functions provide application programs with the ability to invoke user-defined or built-in vendor-specific SQL functions from data services.
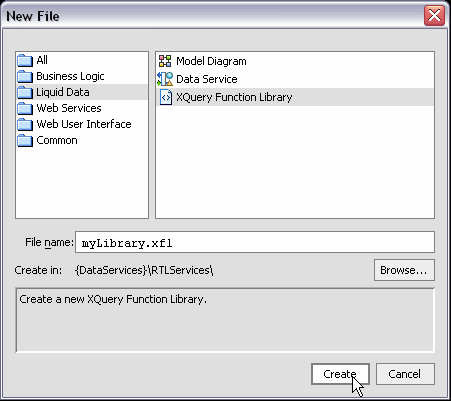
XQuery function libraries can be created in two ways:
New XQuery Function Library option.
XQuery function libraries are available from the Data Services Palette.

An XQuery function library (XFL) can contain any number of functions. In an AquaLogic Data Services Platform-enabled project, you will find that XFL Design View is similar to the data service Design View (shown in Sample Data Service). The primary differences are:
The tabular modes available in data services — Source View, XQuery Editor View, Test View, and Query Plan View — are available to XQuery function libraries as well. Similarly, XFL functions have associated properties that can be viewed through the Property Editor.
| Note: | XFL files also play an important role in creating inverse functions. See Using Inverse Functions to Improve Query Performance in Best Practices and Advanced Topics. |
It is not difficult to make a function in a data service available throughout your project as an XML function library. For example, the following function is available in the RTLApp's DataServices/RTLServices/Credit Card data service (namespace declarations from a separate section of the source file are also included):
declare namespace ns1="ld:DataServices/BillingDB/CREDIT_CARD";
import schema namespace ns0="urn:retailerType" at "ld:DataServices/RTLServices/schemas/CreditCard.xsd";
declare namespace tns="ld:DataServices/RTLServices/CreditCard";
(: ... :)
declare function tns:getCreditCard() as element(ns0:CREDIT_CARD)* {
for $CREDIT_CARD in ns1:CREDIT_CARD()
return <ns0:CREDIT_CARD>
<CreditCardID>{fn:data($CREDIT_CARD/CC_ID)}</CreditCardID>
<CustomerID>{fn:data($CREDIT_CARD/CUSTOMER_ID)}</CustomerID>
<CustomerName>{fn:data($CREDIT_CARD/CC_CUSTOMER_NAME)}</CustomerName>
<CreditCardType>{fn:data($CREDIT_CARD/CC_TYPE)}</CreditCardType>
<CreditCardBrand>{fn:data($CREDIT_CARD/CC_BRAND)}</CreditCardBrand>
<CreditCardNumber>{fn:data($CREDIT_CARD/CC_NUMBER)}</CreditCardNumber>
<LastDigits>{fn:data($CREDIT_CARD/LAST_DIGITS)}</LastDigits>
<ExpirationDate>{fn:data($CREDIT_CARD/EXP_DATE)}</ExpirationDate>
{fn-bea:rename($CREDIT_CARD/STATUS,<Status/>)}
{fn-bea:rename($CREDIT_CARD/ALIAS,<Alias/>)}
<AddressID>{fn:data($CREDIT_CARD/ADDR_ID)}</AddressID>
</ns0:CREDIT_CARD>
};Here are the steps you would take to create this function in an XQuery library:
Source for the XQuery library file containing the CREDIT_CARD function appears below. To simplify, the object is returned as $x rather than as a set of individually-mapped elements.
xquery version "1.0" encoding "WINDOWS-1252";
(::pragma xfl <x:xfl xmlns:x="urn:annotations.ld.bea.com"></x:xfl> ::)
declare namespace tns="lib:DataServices/myXQueryLibrary";
declare namespace ns1="ld:DataServices/BillingDB/CREDIT_CARD";
import schema namespace ns0="urn:retailerType" at "ld:DataServices/RTLServices/schemas/CreditCard.xsd";
declare function tns:getCreditCard() as element(ns1:CREDIT_CARD)* {
for $x in ns1:CREDIT_CARD()
return $x
};
A database function library is an XFL that contains only database function locations and signatures. Such libraries can contain only database functions.
Database functions are designed to extend SQL support beyond that provided through standard JDBC functionality. There are several benefits:
A database function library provides access to two additional types of SQL functions:
Once a function has been registered in a library, it can be become available through XQuery or as SQL:
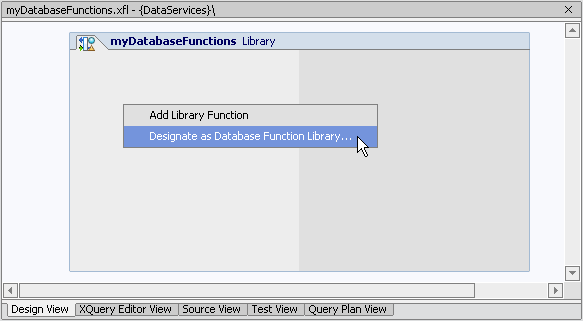
The following example shows how such a library is created:
| Note: | Once you have created your database function library, you can add additional database functions through your XFL Properties Editor (see Figure 2-40). |
XFL database function libraries are available from the Data Services Palette.
| Note: | A mapping of XML to JDBC types can be found in the Using SQL to Access Data Services chapter of the Client Application Developer's Guide. |
You can adjust catalog, schema, package, and XQuery function name settings through the Property Editor (Figure 2-40) at any time.
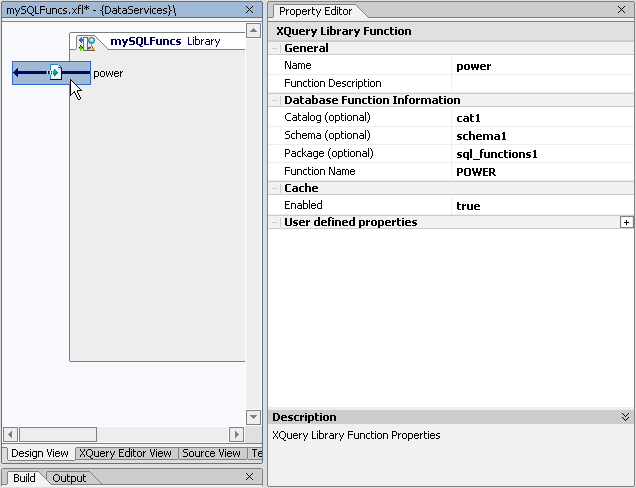
Once your XFL database functions have been published to SQL (as described in Publishing Data Service Functions for SQL Use) and your AquaLogic Data Services Platform application deployed, your functions will be available to client application developers through standard data service calls, including JDBC, the mediator API and, as a Data Service control.
| Note: | If you build a SQL query using a reporting tool, the unqualified JDBC function name is used in the generated SQL. When an application developer invokes an XFL database function, the default catalog and schema name must be defined when the JDBC connection is created. For this reason it is also a requirement that any JDBC connection utilize functions available from a single catalog:schema pair location. |
| Note: | The following is an example URL defining a default catalog and schema for a JDBC connection: |
jdbc:dsp@localhost:7001/myApplication/myCatalog/mySchema
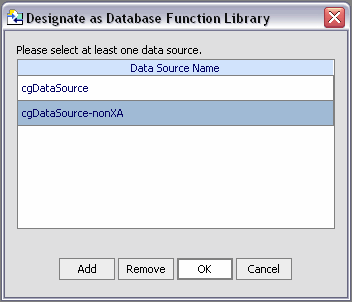
It is easy to associate or disassociate DFL data sources using the XFL Properties Editor. Figure 2-41 shows two data sources associated with a sample XFL database function library: cgDataSource and cgDataSource-nonXA.
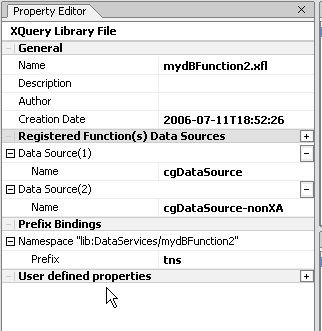
You can change a database name designation by clicking on the database name and then selecting another database from the drop-down list. You can add a new database by clicking the "+" next to the Registered Function(s) Data Sources property. Similarly, you can remove a registered database function data source by clicking the "-" next to that data source name.
When you declare an XFL as a database function library, an underlying pragma statement is generated in Source View identifying your XFL as dedicated to database function declarations.
In Listing 2-1 names of databases available to function declarations are contained in a customNativeFunctions type. (Custom native functions are the same as XFL database functions.)
(::pragma xfl <x:xfl xmlns:x="urn:annotations.ld.bea.com">
<creationDate>
2006-07-11T11:13:18
</creationDate>
<customNativeFunctions>
<relational>
<dataSource>cgDataSource-nonXA</dataSource>
<dataSource>bpmArchDataSource</dataSource>
</relational>
</customNativeFunctions>
</x:xfl> ::)
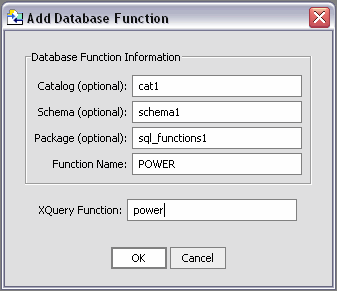
The sample in Listing 2-2 shows code automatically created when you add an XFL database function declaration to your library.
(::pragma function
<f:function xmlns:f="urn:annotations.ld.bea.com" nativeLevel1Container="cat1"
nativeLevel2Container="schema1"
nativeLevel3Container="sql_functions1"
nativeName="POWER">
</f:function>::)
declare function tns:Power() as xdt:anyAtomicType? external;
Notice that function is identified as external to the application.
| Note: | The sequence of dataSource elements carry the names of the relational sources to which the specified functions apply. The native qualified name of each function is captured in the values of: |
"nativeLevelNContainer" (N = 1,2,3)
"nativeName"
For example, the qualified name of a custom SQL function MEDIAN, defined under package STATISTICS, will be represented by the following annotation:
(::pragma function
<f:function xmlns:f="urn:annotations.ld.bea.com" nativeName="MEDIAN" nativeLevel3Container="STATISTICS"/> ::)
The qualified name (the qname) of the XQuery function representing the native function is user-defined.
The native signature of each function is reflected in the signature specified by the XQuery function declaration. In the case of user-defined SQL functions, the SQL type of an input parameter or output of the SQL function (e.g., TIME) is reflected in the corresponding XQuery type in the function signature (e.g., xs:time).
| Note: | It is important that type mappings between XML and SQL be correct. See "XML and SQL Type Mappings" in the Using SQL to Access Data Services chapter of the Client Application Developer's Guide. |
Native functions that expose a certain type of polymorphism, in that their output type is determined by the actual type of one of their parameters, may use the optional annotation element isPolymorphic. The element isPolymorphic accepts the required parameter element as its content. The element "parameter" accepts the index attribute, as described in Table 2-42.
The following example illustrates the use of the isPolymorphic element.
declare namespace stat = "urn:sample";
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com" nativeName="MEDIAN" nativeLevel3Container="STATISTICS">
<isPolymorphic><parameter/></isPolymorphic>
</function>::)
declare function stat:median($x as xdt:anyAtomicType*) as xdt:anyAtomicType external;


|