
|
|
This chapter describes miscellaneous features related to client programming with BEA AquaLogic Data Services Platform. It covers the following topics:
BEA AquaLogic Data Services Platform maintains metadata about data services, application, functions, schemas through Catalog Services, which is a system catalog-type data service. Catalog services provide a convenient way for client-application developers to programmatically obtain information about any AquaLogic Data Services Platform application, data services, schemas, functions, and relationships. Catalog Services are also data services, therefore, you can view them using the AquaLogic Data Services Console, AquaLogic Data Services Platform Palette, and Data Service controls.
Some advantages of using Catalog Services are as follows:
This section provides details about installing and using Catalog Services to access metadata for any AquaLogic Data Services Platform application. It includes the following topics:
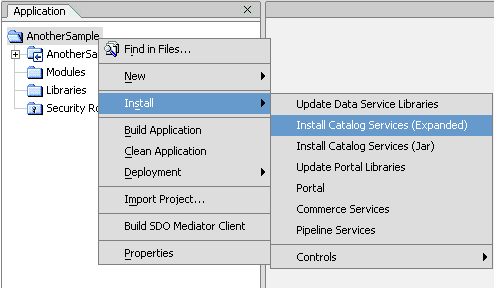
You can install Catalog Services as a project for an AquaLogic Data Services Platform application or as a JAR file that is added to the Library folder in WebLogic Workshop. The Catalog Services project (_catalogservices) contains data services that provide information about the application, folders, data services, functions, schemas, and relationships available with the application.
DataServiceRef and SchemaRef are additional data services, which consist of functions that retrieve the paths to the data services and schemas available with the AquaLogic Data Services Platform application. For more information about the data services and functions available with Catalog Services, refer to Using Catalog Services on page 11-3.
To install Catalog Services as a project:
After installing Catalog Services, the catalog services project, _catalogservices, is created for the AquaLogic Data Services Platform application. All the data services associated with catalog services are available under this project. You can invoke the data service functions to access metadata. The client Mediator API is used to invoke the Catalog Service methods.
The data services available under _catalogservices include:
| Note: | To use data service functions available with Catalog services, refer to the code samples available at: |
| Note: |
http://dev2dev.bea.com/wiki/pub/CodeShare/Sample1/catalogsrv_output.zip |
The following table provides the declaration and description for the getApplication()function in Application.ds.
Table 11-3 provides declaration and description information for the functions available in DataService.ds.
<urn:DataService kind="javaFunction" xmlns:acc="ld:RTLAppDataServices/CustomerDB/Customer" xmlns:urn="urn:metadata.ld.bea.com">
|
||
The following table provides the declaration and description for the functions available in DataServiceRef.ds.
The following table provides the declaration and description for the functions available in Folder.ds.
The following table provides the declaration and description for the functions in Function.ds.
The following table provides the declaration and description for the functions available in Relationship.ds.
| Note: | The functions in Relationship.ds can be used to access metadata only for navigation functions. |
<urn:Relationship xmlns:acc="ld:RTLAppDataServices/CustomerDB/CUSTOMER" xmlns:urn="urn:metadata.ld.bea.com">
|
The following table provides the declaration and description for the functions available in Schema.ds.
The following table provides the declaration and description for the functions available in SchemaRef.ds.
The Filter API enables client applications to apply filtering conditions to the information returned by data service functions. In a sense, filtering allows client applications to extend a data service interface by allowing them to specify more about how data objects are to be instantiated and returned by functions.
The Filter API alleviates data service designers from having to anticipate every possible data view that their clients may require and to implement a data service function for each view. Instead, the designer may choose to specify a broader, more generic interface for accessing a business entity and allow client applications to control views as desired through filters.
Only objects in the function return set that meet the condition are returned to the client. (The evaluation occurs at the server, so objects that are filtered are not passed over the network. Often, objects that are filtered out are not even retrieved from the underlying sources.) A filter is similar to a WHERE clause in an XQuery or SQL statement—it applies conditions to a possible result set. You can apply multiple filter conditions using AND and OR operators. Other operators that be applied to filter conditions are listed in Table 11-10.
| Note: | Filter API Javadoc, as well as other AquaLogic Data Services Platform APIs, is described at AquaLogic Data Services Platform Mediator API Javadoc on page 1-13. |
Filtering capabilities are available to Mediator and Data Service control client applications. You use filter conditions to specify the data you want returned, sort the data, or limit the number of records returned. To use filters in a mediator client application, import the appropriate package and use the supplied interfaces for creating and applying filter conditions. Data service control clients get the interface automatically. When a function is added to a control, a corresponding "WithFilter" function is added as well.
The filter package is named as follows:
com.bea.ld.filter.FilterXQuery; To use a filter, perform the following steps:
FilterXQuerymyFilter = newFilterXQuery();
The addFilter() method has several signatures with different parameters, including the following:
public void addFilter(java.lang.String appliesTo,
java.lang.String field,
java.lang.String operator,
java.lang.String value,
java.lang.Boolean everyChild)
This version of the method takes the following arguments:
appliesTo indicates the node that filtering affects. That is, if a node specified by the field argument does not meet the condition, appliesTo nodes are filtered out. field is the node against which the filtering condition is tested. operator and value together compose the condition statement. The operator parameter specifies the type of comparison to be made against the specified value. See
Table 11-10, Filter Operators, on page 11-16 for information about available operators.everyChild is an optional parameter. It is set to false by default. Specifying true for this parameter indicates that only those child elements that meet the filter criteria will be returned. For example, by specifying an operator of GREATER_THAN (or ">") and a value of 1000, only records for customers where all orders are over 1000 will be returned. A customer that has an order amount less than 1000 will not be returned, although other order amounts might be greater than 1000.The following is an example of an add filter method where those orders with an order amount greater than 1000 will be returned (note that everyChild is not specified, so order amounts below 1000 will be returned):
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
">",
"1000");CUSTOMER custDS = CUSTOMER.getInstance(ctx, "RTLApp");
custDS.setFilterCondition(myFilter);
If a filter condition applied to a specified element value resolves to false, an element is not included in the result set. The element that is filtered out is specified as the first argument to the addFilter() function.
The effects of a filter can vary, depending on the desired results. For example, consider the CUSTOMERS data object shown in Figure 11-1. It contains several complex elements (CUSTOMER and ORDERS) and several simple elements, including ORDER_AMOUNT. You can apply a filter to any elements in this hierarchy.
In general, with nested XML data, a condition such as "CUSTOMER/ORDER/ORDER_AMOUNT > 1000" can affect what objects are returned in several ways. For example, it can cause all CUSTOMER objects to be returned, but filter ORDERS that have an amount less than 1000.
Alternatively, it can cause only CUSTOMER objects to be returned that have at least one large order, and all ORDER objects are returned for every CUSTOMER. Further, it can cause only CUSTOMER objects to be returned for which every ORDER is greater than 1000. For example,
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter( "CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000",true);
Note that in the optional fourth parameter everyChild = true, by default this attribute is false. By setting this parameter to true, only those CUSTOMER objects for which every ORDER is greater than 1000 will be returned.
The following examples show how filters can be applied in several different ways:
FilterXQuery myFilter = new FilterXQuery();
Filter f1 = myFilter.createFilter(
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER", f1);
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
The last example is a compound filter; that is, a filter with two conditions. Listing 11-1 uses the AND operator to apply a combination of filters to a result set, given a data service instance customerDS.
FilterXQuery myFilter = new FilterXQuery();
Filter f1 = myFilter.createFilter("CUSTOMER_PROFILE/ADDRESS/ISDEFAULT",
FilterXQuery.NOT_EQUAL,"0");
Filter f2 = myFilter.createFilter("CUSTOMER/ADDRESS/STATUS",
FilterXQuery.EQUAL,
"\"ACTIVE\"");
Filter f3 = myFilter.createFilter(f1,f2, FilterXQuery.AND);
Customer customerDS = Customer.getInstance(ctx, "RTLApp");
CustomerDS.setFilterCondition(myFilter);
Another type of filter you can use in client application code is an ordering condition—you specify the order (descending, ascending) in which results should be returned from the data service. The method (addOrderBy(), in the FilterXQuery class), takes a property name as the criterion upon which the ascending or descending decision is based. Listing 11-2 provides an example of creating a filter that will return customer profiles in ascending order, based on the date each person became a customer.
FilterXQuery myFilter = new FilterXQuery();
myFilter.addOrderBy("CUSTOMER_PROFILE",
"CustomerSince" ,FilterXQuery.ASCENDING);
ds.setFilterCondition(myFilter);
DataObject objArrayOfCust = (DataObject) ds.invoke("getCustomer", null);
Similarly, you can set the maximum number of results that can be returned from a function. The setLimit() function limits the number of elements in an array element to the specified number. And on a repeating node, it makes sense to specify a limit on the results to be returned. (Setting the limits on non-repeating nodes does not truncate the results.)
Listing 11-3 shows how to use the setLimit() method. It limits the number of active address in the result set (filtering out active addresses) to 10 given a data service instance ds.
FilterXQuery myFilter = new FilterXQuery();
Filter f2 = myFilter.createFilter("CUSTOMER_PROFILE/ADDRESS",
FilterXQuery.EQUAL,"\"INACTIVE\"");
myFilter.addFilter("CUSTOMER_PROFILE", f2);
myFilter.setLimit("CUSTOMER_PROFILE", "10");
ds.setFilterCondition(myFilter);
An ad hoc query is an XQuery function that is not defined as part of a data service, but is instead defined in the context of a client application. Ad hoc queries are typically used in client applications to invoke data service functions and refine the results in some way. You can use an ad hoc query to execute any valid XQuery expression against a data service. The expression can target the actual data sources that underlie the data service, or can use the functions and procedures hosted by the data service.
To execute an XQuery expression, use the PreparedExpression interface, available in the Mediator API. Similar to JDBC's PreparedStatement interface, the PreparedExpression interface takes the XQuery expression as a string in its constructor, along with the JNDI server context and application name. After constructing the prepared expression object in this way, you can call the executeQuery( ) method on it. If the ad hoc query invokes data service functions or procedures, the data service's namespace must be imported into query string before you can reference the methods in your ad hoc query.
Listing 11-4 shows a complete example; the code returns the results of a data service function named getCustomers( ), which is in the namespace:
ld:DataServices/RTLServices/Customer
import com.bea.ld.dsmediator.client.PreparedExpression;
String queryStr =
"declare namespace ns0=\"ld:DataServices/RTLServices/Customer\";" +
"<Results>" +
" { for $customer_profile in ns0:getCustomer()" +
" return $customer_profile }" +
"</Results>";
PreparedExpression adHocQuery =
DataServiceFactory.prepareExpression(context,"RTLApp",queryStr );
XmlObject objResult = (XmlObject) adHocQuery.executeQuery();
AquaLogic Data Services Platform passes information back to the ad hoc query caller as an XMLObject data type. Once you have the XMLObject, you can downcast to the data type of the deployed XML schema. Since XMLObject has only a single root type, if the data service function returns an array, your ad hoc query should include a root element as a container for the array.
For example, the ad hoc query shown in Listing 11-4 specifies a <Results> container object to hold the array of CUSTOMER_PROFILE elements that will be returned by the getCustomer() data service function.
Security policies defined for a data service apply to the data service calls in an ad hoc query as well. If an ad hoc query uses secured resources, the appropriate credentials must be passed when creating the JNDI initial context. (For more information, see Obtaining a WebLogic JNDI Context for AquaLogic Data Services Platform.)
As with the PreparedStatement interface of JDBC, the PreparedExpression interface supports dynamically binding variables in ad hoc query expressions. PreparedExpression provides several methods (bindType( ) methods; see Table 11-12), for binding values of various data types.
To use the bindType methods, pass the variable name as an XML qualified name (QName) along with its value; for example:
adHocQuery.bindInt(new QName("i"),94133);Listing 11-5 shows an example of using a bindInt() method in the context of an ad hoc query.
PreparedExpression adHocQuery = DataServiceFactory.preparedExpression(
context, "RTLApp",
"declare variable $i as xs:int external;
<result><zip>{fn:data($i)}</zip></result>");
adHocQuery.bindInt(new QName("i"),94133);
XmlObject adHocResult = adHocQuery.executeQuery();
| Note: | For more information on QNames, see: |
Listing 11-6 shows a complete ad hoc query example, using the PreparedExpression interface and QNames to pass values in bind methods.
import com.bea.ld.dsmediator.client.DataServiceFactory;
import com.bea.ld.dsmediator.client.PreparedExpression;
import com.bea.xml.XmlObject;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.xml.namespace.QName;
import weblogic.jndi.Environment;
public class AdHocQuery
{
public static InitialContext getInitialContext() throws NamingException {
Environment env = new Environment();
env.setProviderUrl("t3://localhost:7001");
env.setInitialContextFactory("weblogic.jndi.WLInitialContextFactory");
env.setSecurityPrincipal("weblogic");
env.setSecurityCredentials("weblogic");
return new InitialContext(env.getInitialContext().getEnvironment());
}
public static void main (String args[]) {
System.out.println("========== Ad Hoc Client ==========");
try {
StringBuffer xquery = new StringBuffer();
xquery.append("declare variable $p_firstname as xs:string external; \n");
xquery.append("declare variable $p_lastname as xs:string external; \n");
xquery.append(
"declare namespace ns1=\"ld:DataServices/MyQueries/XQueries\"; \n");
xquery.append(
"declare namespace ns0=\"ld:DataServices/CustomerDB/CUSTOMER\"; \n\n");
xquery.append("<ns1:RESULTS> \n");
xquery.append("{ \n");
xquery.append(" for $customer in ns0:CUSTOMER() \n");
xquery.append(" where ($customer/FIRST_NAME eq $p_firstname \n");
xquery.append(" and $customer/LAST_NAME eq $p_lastname) \n");
xquery.append(" return \n");
xquery.append(" $customer \n");
xquery.append(" } \n");
xquery.append("</ns1:RESULTS> \n");
PreparedExpression pe = DataServiceFactory.prepareExpression(
getInitialContext(), "RTLApp", xquery.toString());
pe.bindString(new QName("p_firstname"), "Jack");
pe.bindString(new QName("p_lastname"), "Black");
XmlObject results = pe.executeQuery();
System.out.println(results);
} catch (Exception e) {
e.printStackTrace();
}
}
This section discusses further programming topics related to client programming with the Data Service Mediator API. It includes the following topics:
When a function in the standard data service interface is called, the requested data is first materialized in the system memory of the server machine. If the function is intended to return a large amount of data, in-memory materialization of the data may be impractical. This may be the case, for example, for administrative functions that generate "inventory reports" of the data exposed by AquaLogic Data Services Platform. For such cases, AquaLogic Data Services Platform can serve information as an output stream.
AquaLogic Data Services Platform leverages the WebLogic XML Streaming API for its streaming interface. The WebLogic Streaming API is similar to the standard SAX (Streaming API for XML) interface. However, instead of contending with the complexity of the event handlers used by SAX, the WebLogic Streaming API lets you use stream-based (or pull-based) handling of XML documents in which you step through the data object elements. As such, the WebLogic Streaming API affords more control than the SAX interface, in that the consuming application initiates events, such as iterating over attributes or skipping ahead to the next element, instead of reacting to them.
| Note: | The streaming API is intended to be used when large result sets are needed and cannot be easily materialized in memory. It may be advisable to run your data service queries on different servers in order to simultaneously support both real-time queries and large, batch-oriented queries. However, if two servers are not possible, then consider running the streaming API queries during off-peak times. |
In AquaLogic Data Services Platform only server-side steaming is supported. Thus a JSP, which is hosted on the server, can leverage the streaming API. However, an external Java application could not.
You can get AquaLogic Data Services Platform information as a stream by using either an ad hoc or an untyped data service interface.
| Note: | Streaming is not supported through static interfaces. For more information on the WebLogic Streaming API, see "Using the WebLogic XML Streaming API" at: http://download.oracle.com/docs/cd/E13222_01/wls/docs81/xml/xml_stream.html. |
The streaming interface can be found in the following classes in the com.bea.ld.dsmediator.client package:
Using these interfaces is very similar to using their SDO mediator client API equivalents. However, instead of a document object, they return data as an XMLInputStream. For functions that take complex elements (possibly with a large amount of data) as input parameters, XMLInputStream is supported as an input argument as well. The following is a example:
StreamingDataService ds = DataServiceFactory.newStreamingDataService(
context,
"ld:DataServices/RTLServices/Customer");
XMLInputStream stream = ds.invoke("getCustomerByCustID", "CUSTOMER0");
The previous example shows the dynamic streaming interface. The following example uses an ad hoc query:
String adhocQuery =
"declare namespace ns0=\"ld:DataServices/RTLServices/Customer\";\n" +
"declare variable $cust_id as xs:string external;\n" +
"for $customer in ns0:getCustomerByCustID($cust_id)\n" +
"return\n" +
" $customer\n";
StreamingPreparedExression expr =
DataServiceFactory.prepareExpression(context, adhocQuery);
If you have external variables in the query string (adhocQuery in the above example), you will also need to do the following:
expr.bindString("$cust_id","CUSOMER0");
XMLInputStream xml = expr.executeQuery();| Note: | For more information on using the dynamic and ad hoc interfaces, see Using a Dynamic Mediator API in Accessing Data Services from Java Clients. |
| Note: | Javadoc for the StreamingDataService interface and other AquaLogic Data Services Platform APIs is described at: AquaLogic Data Services Platform Mediator API Javadoc on page 1-13. |
Listing 11-7 shows an example of a method that reads the XML input stream. This method uses an attribute iterator to print out attributes and namespaces in an XML event and throws an XMLStream exception if an error occurs.
import weblogic.xml.stream.Attribute;
import weblogic.xml.stream.AttributeIterator;
import weblogic.xml.stream.ChangePrefixMapping;
import weblogic.xml.stream.CharacterData;
import weblogic.xml.stream.XMLEvent;
import weblogic.xml.stream.EndDocument;
import weblogic.xml.stream.EndElement;
import weblogic.xml.stream.EntityReference;
import weblogic.xml.stream.Space;
import weblogic.xml.stream.StartDocument;
import weblogic.xml.stream.XMLInputStream;
import weblogic.xml.stream.XMLInputStreamFactory;
import weblogic.xml.stream.XMLName;
import weblogic.xml.stream.XMLStreamException;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class ComplexParse {
public void parse(XMLEvent event)throws XMLStreamException
{
switch(event.getType()) {
case XMLEvent.START_ELEMENT:
StartElement startElement = (StartElement) event;
System.out.print("<" + startElement.getName().getQualifiedName() );
AttributeIterator attributes = startElement.getAttributesAndNamespaces();
while(attributes.hasNext()){
Attribute attribute = attributes.next();
System.out.print(" " + attribute.getName().getQualifiedName() +
"='" + attribute.getValue() + "'");
}
System.out.print(">");
break;
case XMLEvent.END_ELEMENT:
System.out.print("</" + event.getName().getQualifiedName() +">");
break;
case XMLEvent.SPACE:
case XMLEvent.CHARACTER_DATA:
CharacterData characterData = (CharacterData) event;
System.out.print(characterData.getContent());
break;
case XMLEvent.COMMENT:
// Print comment
break;
case XMLEvent.PROCESSING_INSTRUCTION:
// Print ProcessingInstruction
break;
case XMLEvent.START_DOCUMENT:
// Print StartDocument
break;
case XMLEvent.END_DOCUMENT:
// Print EndDocument
break;
case XMLEvent.START_PREFIX_MAPPING:
// Print StartPrefixMapping
break;
case XMLEvent.END_PREFIX_MAPPING:
// Print EndPrefixMapping
break;
case XMLEvent.CHANGE_PREFIX_MAPPING:
// Print ChangePrefixMapping
break;
case XMLEvent.ENTITY_REFERENCE:
// Print EntityReference
break;
case XMLEvent.NULL_ELEMENT:
throw new XMLStreamException("Attempt to write a null event.");
default:
throw new XMLStreamException("Attempt to write unknown event["
+event.getType()+"]");
}
}
You can write serialized results of a data service function to a file using a WriteOutputToFile method. Such a function is generated automatically for each function defined in the data service. For security reasons it writes only to a file on the server's file system.
These functions provide services that are similar to streaming APIs. They are intended for creating reports or an inventory of data service information. However, the writeOutputToFile method can be invoked from a remote mediator API (in contrast with the streaming API described in Using the Streaming Interface on page 11-26).
The following example shows how to write to a file from the untyped interface.
StreamingDataService sds =
DataServiceFactory.newStreamingDataService(
context,"RTLApp","ld:DataServices/RTLServices/Customer"");
sds.writeOutputToFile("getCustomer", null, "streamContent.txt");
sds.closeStream();
| Note: | No attempt to create folders is made. In the above example, if you want to write data inside a folder named myData that folder should be present in the server domain root prior to the write operation. |


|