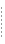

|
|
This chapter describes how to configure application-level settings for AquaLogic Data Services Platform. The chapter contains the following sections:
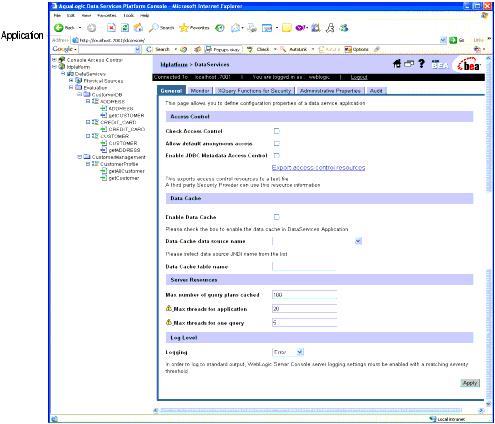
You can view and configure runtime settings for AquaLogic Data Services Platform-enabled applications, including access control, cache settings, server resources (including thread usage), and log levels.
| Note: | For details on accessing the Data Services Platform Console (named ldconsole) see Launching the AquaLogic Data Services Platform Console. |
To specify general application settings:
The General settings page appears, as illustrated in Figure 5-1. Note that you must be logged into the console using a user name with administrator privileges.
Table 5-1 lists the application settings available under the General tab.
|
For more information about caching, see Configuring the Query Results Cache.
|
|||
The maximum number of threads in the AquaLogic Data Services Platform server pool used to handle query requests.
The default setting is 20. The minimum setting is 1. If the specified value is invalid, the server uses the default value of 20.
For more information on configuring thread counts, see Guidelines for Setting Server Thread Count.
|
|||
The maximum number of threads allowed for a single query. Use this to limit the number of threads spawned by a single query. The actual number of threads used will not exceed the maximum number of threads specified in Maximum Threads, regardless of the Maximum Number of Threads Per Query setting.
The default setting is 4. The minimum setting is 1. If the specified value is invalid, the server uses the default value of 4.
For more information on configuring thread counts, see Guidelines for Setting Server Thread Count.
|
|||
|
|
It is frequently desirable to change the location of data sources or names of other artifacts as you move applications from development to staging to production. For example, if you are using "dummy" data sources during development in order to protect confidential or otherwise secured information, you will at some point need to substitute a new data source with the actual data for the test version. You can make these changes through the Data Services Platform Console.
In modifying end points you are not limited to the name and location of a data source. It is also possible to change the target names of subordinate artifacts. In the case of relational sources this includes catalog name, schema names, package names, table names, and stored procedure names.
| Note: | Once set, end point modifications are effective until they are further modified or reverted to the original name. To assign the end point name its original value, simply click Reset to original value. This option will not revert the value to the previous setting, it will directly revert it to the original name. So, if you have assigned a few names over time, the moment you click Reset to original value, the values revert to the same as those in the Original Value column. |
| Note: | Whenever you change the end point for an artifact you need to ensure that the intrinsic aspects of that artifact remain identical with the old source. In the case of a relational source properties such as Vendor Type and Version must be identical. |
When you change the end point of a particular object, the new end point appears in brackets next to the original name. Figure 5-3 below displays the original data source name, and the new data source name (in square brackets) adjacent to it.
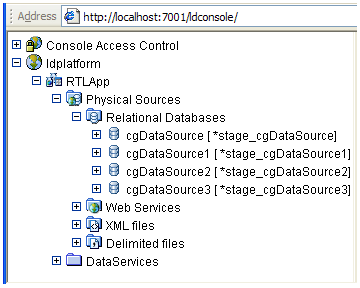
Table 5-2 identifies the artifacts whose end point settings can be changed.
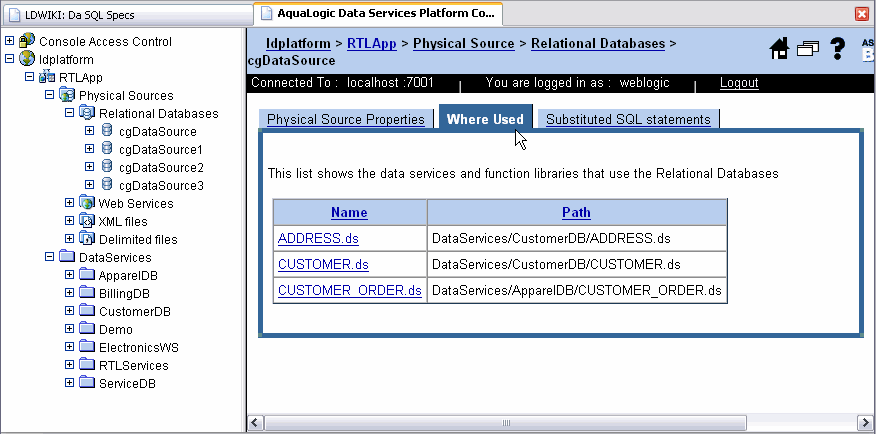
You can view a list of data services and function libraries that use the defined relational databases. Click the Where Used tab to view the list of data services and their specific paths (Figure 5-4).
AquaLogic Data Services Platform uses SQL language to access relational data sources. At the compilation time built-in query optimizer determines the best execution strategy for backend sources. Then SQL queries are generated and submitted to underlying databases.
SQL queries generated by the relational wrapper are specific to each underlying database. While the SQL queries that are generated typically produce good results, there are cases however when further optimization of the generated queries is desirable. In most RDBS systems such optimization is done through execution hints.
SQL statement substitution allows you to add hints to generated SQL queries by providing edited SQL statements that will be executed instead of the query that is generated by default by AquaLogic Data Services Platform.
| WARNING: | Unlike SQL statements generated by AquaLogic Data Services Platform, substituted SQL statements are passed to the underlying database in an unvalidated form. For this reason users are strongly advised against using this feature for any purpose other than providing hints to the database. It is also recommended that prior to deployment any substituted SQL statement be tested against its generated counterpart to make sure that the expected performance advantage is being obtained. |
AquaLogic Data Services Platform server maintains a substitution table between the original generated SQL queries and any replacement queries supplied by the user. Only SQL queries specified by user will be substituted.
The AquaLogic Data Services Platform administrator defines and maintains substitution queries through the AquaLogic Data Services Console.
The replacement query is executed instead of the original SQL query. The AquaLogic Data Services Platform runtime engine reads the SQL result set using type/column information of the original query. Incorrect substitution which violates the conditions listed in Requirements for SQL Statement Substitution might lead to the following problems:
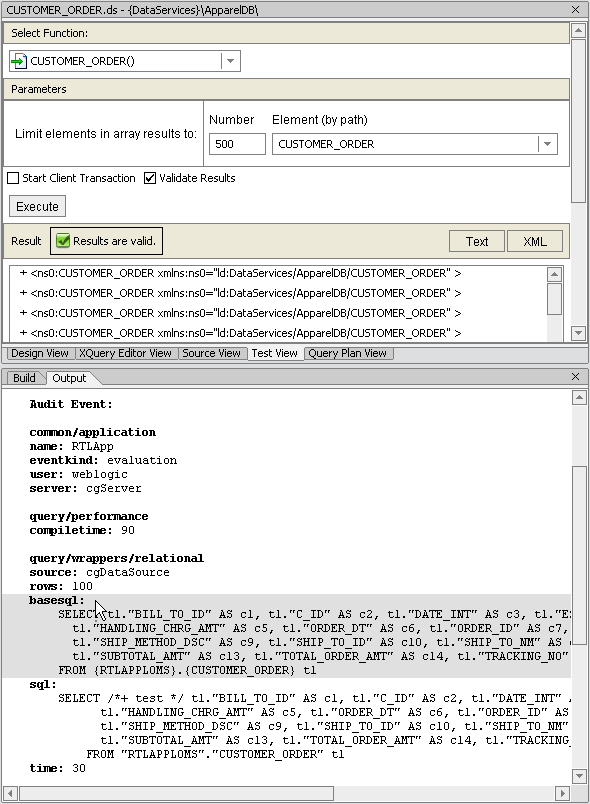
In both the generated and substitute queries, a special syntax is used to support externalized end points (see Modifying Data Source End Points for details). The following substituted queries shows such this special syntax (emphasis added):
SELECT /*+ FIRST_ROWS (10)*/ t1."BILL_TO_ID" AS c1, t1."C_ID" AS c2, t1."DATE_INT" AS c3, t1."ESTIMATED_SHIP_DT" AS c4,
t1."HANDLING_CHRG_AMT" AS c5, t1."ORDER_DT" AS c6, t1."ORDER_ID" AS c7, t1."SALE_TAX_AMT" AS c8,
t1."SHIP_METHOD_DSC" AS c9, t1."SHIP_TO_ID" AS c10, t1."SHIP_TO_NM" AS c11, t1."STATUS" AS c12,
t1."SUBTOTAL_AMT" AS c13, t1."TOTAL_ORDER_AMT" AS c14, t1."TRACKING_NO" AS c15
FROM {RTLAPPLOMS}.{CUSTOMER_ORDER} t1
| Note: | If you are adding SQL fragments (such as string literals) in your substituted SQL statement, you also need to use the convention of doubling opening curlie braces. |
| Note: | For example: |
SELECT t1.ID FROM CUSTOMER() WHERE $i/ID > `a{bee}c' return $i/IDSELECT t1.ID FROM {CUSTOMER} t1 WHERE t1.ID > `a{{bee}c'| Note: | As needed you should specify replacement queries using the same name placeholders as the original query. At the end of the SQL generation stage these original names will be replaced with the current end point names. The original name will be used if no endpoint setting is found. |
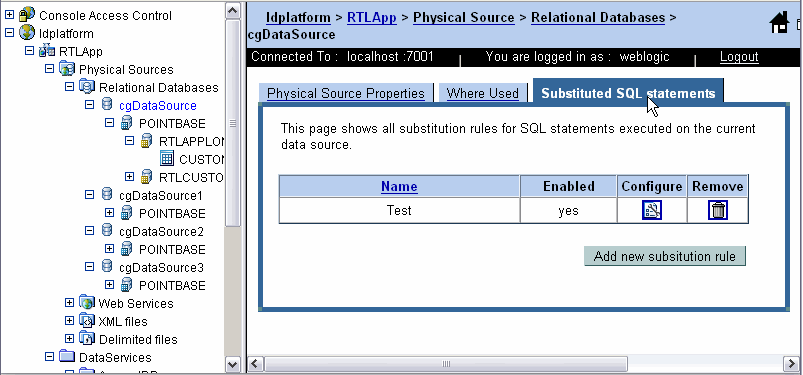
Substitute SQL statements are created and registered in the Data Services Platform Console using the Substituted SQL Statements option (see Figure 5-4).
The options available include:
When you create a substitute SQL query you need to provided the following items of information:
Entries must be made in all fields but the description, which is optional.
The system automatically tracks creation and last modified dates.
There are several requirements regarding the substituted SQL query:
| Note: | For queries using sub-queries only the outermost subquery must preserve column aliases, inner subqueries need not do so. |
The order in which SQL statement substitutions are established is not fixed. Thus the example in this section and the steps involved are only one approach to creating and testing SQL statement substitution.
http://localhost:7001/ldconsole
SELECT t1."BILL_TO_ID" AS c1, t1."C_ID" AS c2, t1."DATE_INT" AS c3, t1."ESTIMATED_SHIP_DT" AS c4,
t1."HANDLING_CHRG_AMT" AS c5, t1."ORDER_DT" AS c6, t1."ORDER_ID" AS c7, t1."SALE_TAX_AMT" AS c8,
t1."SHIP_METHOD_DSC" AS c9, t1."SHIP_TO_ID" AS c10, t1."SHIP_TO_NM" AS c11, t1."STATUS" AS c12,
t1."SUBTOTAL_AMT" AS c13, t1."TOTAL_ORDER_AMT" AS c14, t1."TRACKING_NO" AS c15
FROM {RTLAPPLOMS}.{CUSTOMER_ORDER} t1
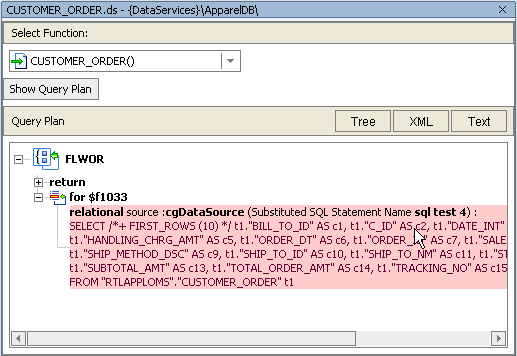
SELECT /*+ FIRST_ROWS (10)*/ t1."BILL_TO_ID" AS c1, t1."C_ID" AS c2, t1."DATE_INT" AS c3, t1."ESTIMATED_SHIP_DT" AS c4,
t1."HANDLING_CHRG_AMT" AS c5, t1."ORDER_DT" AS c6, t1."ORDER_ID" AS c7, t1."SALE_TAX_AMT" AS c8,
t1."SHIP_METHOD_DSC" AS c9, t1."SHIP_TO_ID" AS c10, t1."SHIP_TO_NM" AS c11, t1."STATUS" AS c12,
t1."SUBTOTAL_AMT" AS c13, t1."TOTAL_ORDER_AMT" AS c14, t1."TRACKING_NO" AS c15
FROM {RTLAPPLOMS}.{CUSTOMER_ORDER} t1
| WARNING: | Unlike SQL statements generated by AquaLogic Data Services Platform, substituted SQL statements are passed to the underlying database in an unvalidated form. For this reason users are strongly advised against using this feature for any purpose other than providing hints to the database. It is also recommended that prior to deployment any substituted SQL statement be tested against its generated counterpart to make sure that the expected performance advantage is being obtained. |
The optimal thread count settings you configure depends on the physical resources of the machine on which you deploy AquaLogic Data Services Platform, the anticipated load, and the type of application you are deploying. Increasing the number of threads can accelerate processing, but since each thread consumes memory, you must achieve a balance based on the available resources.
Use the following general guidelines for settings the thread count:
AquaLogic Data Services Platform only uses the thread pool for acquiring web service calls; threads are only spawned when web services are invoked by queries. Therefore, an application that does not rely on web service content can have a relatively low thread count setting.
For more information on tuning performance for the WebLogic Server and applications, see the following:
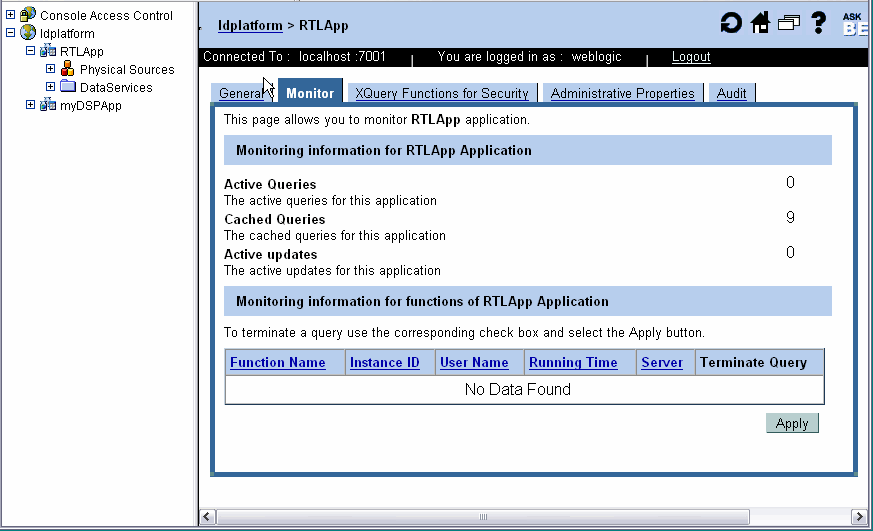
You can view statistics and status information for a AquaLogic Data Services Platform application, particularly relating to query activities, using the Monitor tab. You can also monitor active application processes, displaying information such as the user who initiated the process, the time is has been running, and the number of cached entries for the process type.
The General settings page appears. Note that you must be logged into the console using a user name with administrator privileges.
The monitoring information for the application appears, as illustrated in Figure 5-9.
Table 5-3 describes the information displayed in the Monitor tab.
Once invoked, a data service function runs until either it gets a result or a time-out expires (assuming a time-out period is set). The time-out setting enables you to specify, in the query, the maximum time a query should wait for unresponsive data sources.
In some cases, it may be necessary to cancel the execution of a function. The Monitor tab enables you to view and cancel currently running queries. The page also displays the user associated with the query and cache information.
When you terminate a process, the operation in progress finishes, then the process completes without executing subsequent nodes.
| Note: | The submit query is rolled back only in cases when you are using the XA driver. |
To terminate function execution:
The General settings page appears. (Note that you must be logged into the console using a user name with administrator privileges.)
The list of functions currently running appears in the functions table.
A confirmation dialog box is displayed.
| Note: | Terminating a query triggers a weblogic.xml.query.exceptions.XQuerySystemException on the client. |
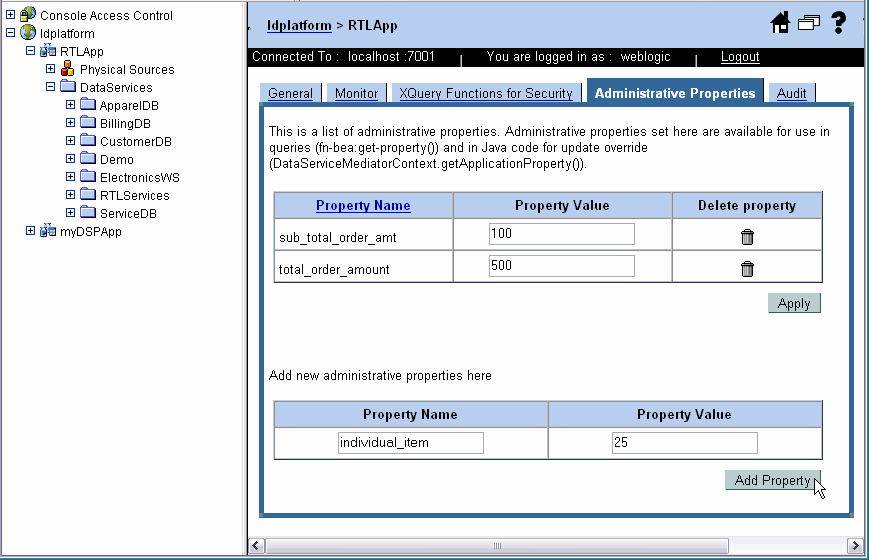
An administrative property is a user-defined property that you can configure using the AquaLogic Data Services Console. The value of an administrative property can be used in XQuery functions, either in data service functions or security XQuery functions.
| Note: | For information on security XQuery functions, see Securing AquaLogic Data Services Platform Resources. |
An administrative property is a convenient way of having function parameters that can be easily changed by the administrator, without having to modify the body of either the data service function or security XQuery function.
The administrative property has application scope — any data service in the application can use the property value. The property value can be accessed using XQuery with the BEA function get-property(). The function takes the name of the property as an argument and returns the value as a string. It also takes an argument that serves as the default value for the parameter. This value is used if the property is not configured in the console.
The following shows a complete example of an XQuery Function Library function using an administrative property:
declare function f1:getMaximumAccountViewable() as xsd:decimal {
let $amount := fn-bea:get-property("maxAccountValue", "1000.00")
cast as xsd:decimal
return $amount
};To manage administrative properties:
Table 5-4 describes the information displayed in the Administrative Properties tab:
The name must match the name property passed to the get-property() function used to access the properties value. For example:
fn-bea:get-property("maxAccountValue", "1") You can change this value later, if required.
In some instances, AquaLogic Data Services Platform may not be able to read data from a database table because another application has locked the table, causing queries issued by AquaLogic Data Services Platform to be queued until the application releases the lock. To prevent this, you can set the transaction isolation to read uncommitted in the JDBC connection pool on your WebLogic Server.
To set the transaction isolation level:
http://<HostName>:<Port>/console
For example, to start the Administration Console for a local instance of WebLogic Server (running on your own machine), type the following URL in a web browser address field:
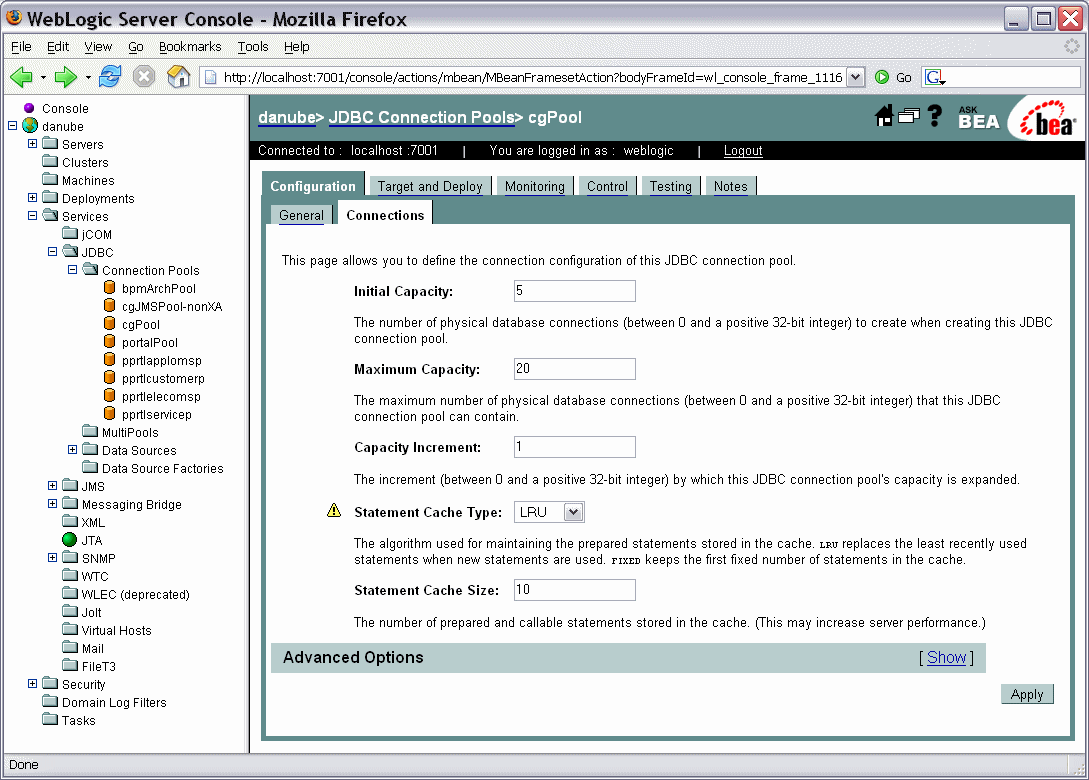
 JDBC Connection Pools under the domain in which the AquaLogic Data Services Platform application runs, and click the name of the connection pool you want to configure.
JDBC Connection Pools under the domain in which the AquaLogic Data Services Platform application runs, and click the name of the connection pool you want to configure.The Connections tab appears, as illustrated in Figure 5-11.
The page expands to include the Advanced Options section.
SQL SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED


|
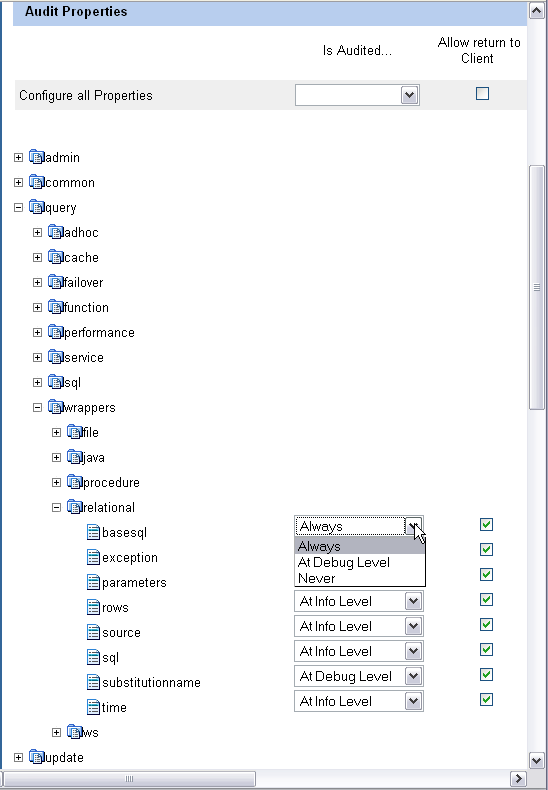
 ) next to the property.
) next to the property.