

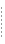

|
|
This topic includes the following sections:
Before a message can be sent from one process to another, a buffer must be allocated for the message data. BEA Tuxedo ATMI clients use typed buffers to send messages to ATMI servers. A typed buffer is a memory area with a category (type) and optionally a subcategory (subtype) associated with it. Typed buffers make up one of the fundamental features of the distributed programming environment supported by the BEA Tuxedo system.
Why typed? In a distributed environment, an application may be installed on heterogeneous systems that communicate across multiple networks using different protocols. Different types of buffers require different routines to initialize, send and receive messages, and encode and decode data. Each buffer is designated as a specific type so that the appropriate routines can be called automatically without programmer intervention.
The following table lists the typed buffers supported by the BEA Tuxedo system and indicates whether or not:
If any routing functions are required, the application programmer must provide them as part of the application.
Undefined array of characters, any of which can be NULL. This typed buffer is used to handle the data opaquely, as the BEA Tuxedo system does not interpret the semantics of the array. Because a CARRAY is not self-describing, the length must always be provided during transmission. Encoding and decoding are not supported for messages sent between machines because the bytes are not interpreted by the system.
|
|||||
Proprietary BEA Tuxedo system type of self-describing buffer in which each data field carries its own identifier, an occurrence number, and possibly a length indicator. Because all data manipulation is done via FML function calls rather than native C statements, the FML buffer offers data-independence and greater flexibility at the expense of some processing overhead.
For more information about the FML buffer, see Using an FML Typed Buffer.
|
|||||
Equivalent to FML but uses 32 bits for field identifiers and lengths of fields, which allows for larger and more fields and, consequently, larger overall buffers.
For more information about the FML32 buffer, see Using an FML Typed Buffer.
|
|||||
C structure defined by the application. VIEW types must have subtypes that designate individual data structures. A
view description file, in which the fields and types that appear in the data structure are defined, must be available to client and server processes that use a data structure described in a VIEW typed buffer. Encoding and decoding are performed automatically if the buffer is passed between machines of different types.
For more information about the VIEW buffer, see Using a VIEW Typed Buffer.
|
|||||
Equivalent to VIEW but uses 32 bits for length and count fields, which allows for larger and more fields and, consequently, larger overall buffers.
For more information about the VIEW32 buffer, see Using a VIEW Typed Buffer.
|
|||||
|
The routing of an XML document can be based on element content, or on element type and an attribute value. The XML parser, such as the Apache Xerces C++ Version 2.5 parser available in BEA Tuxedo 9.x, determines the character encoding being used; if the encoding differs from the native character sets (US-ASCII or EBCDIC) used in the BEA Tuxedo configuration files (UBBCONFIG(5) and DMCONFIG(5)), the element and attribute names are converted to US-ASCII or EBCDIC.
For more information about the XML buffer and the Xerces C++ parser, see Using an XML Typed Buffer and the Apache Xerces C++ Parser.
|
|||||
Character array for multibyte characters—available in BEA Tuxedo 8.1. For more information about the MBSTRING buffer, see Using an MBSTRING Typed Buffer.
|
All buffer types are defined in a file called tmtypesw.c in the $TUXDIR/lib directory. Only buffer types defined in tmtypesw.c are known to your client and server programs. You can edit the tmtypesw.c file to add or remove buffer types. In addition, you can use the BUFTYPE parameter (in UBBCONFIG) to restrict the types and subtypes that can be processed by a given service.
The tmtypesw.c file is used to build a shared object or dynamic link library. This object is dynamically loaded by both BEA Tuxedo administrative servers, and application clients and servers.
Initially, no buffers are associated with a client process. Before a message can be sent, a client process must allocate a buffer of a supported type to carry a message. A typed buffer is allocated using the tpacall (3c) function, as follows:
char*
tpalloc(char *type, char *subtype, longsize)
The following table describes the arguments to the tpalloc() function.
Pointer to the name of a subtype being specified (in the
view description file) for a
VIEW, VIEW32, or X_COMMON typed buffer.
|
|
|
The BEA Tuxedo system automatically associates a default buffer size with all typed buffers except
CARRAY, X_OCTET, and XML, which require that you specify a size, so that the end of the buffer can be identified.
For all typed buffers other than
CARRAY, X_OCTET, and XML, if you specify a value of zero, the BEA Tuxedo system uses the default associated with that typed buffer. If you specify a size, the BEA Tuxedo system assigns the larger of the following two values: the specified size or the default size associated with that typed buffer.
The default size for all typed buffers other than
STRING, CARRAY, X_OCTET, and XML is 1024 bytes. The default size for STRING typed buffers is 512 bytes. There is no default value for CARRAY, X_OCTET, and XML; for these typed buffers you must specify a size value greater than zero. If you do not specify a size, the argument defaults to 0. As a result, the tpalloc() function returns a NULL pointer and sets tperrno to TPEINVAL.
|
The VIEW, VIEW32, X_C_TYPE, and X_COMMON typed buffers require the subtype argument, as shown in the following example.
struct aud *audv; /* pointer to aud view structure */
. . .
audv = (struct aud *) tpalloc("VIEW", "aud", sizeof(struct aud));
. . .
The following example shows how to allocate an FML typed buffer. Note that a value of NULL is assigned to the subtype argument.
FBFR *fbfr; /* pointer to an FML buffer structure */
. . .
fbfr = (FBFR *)tpalloc("FML", NULL, Fneeded(f, v))
. . .
The following example shows how to allocate a CARRAY typed buffer, which requires that a size value be specified.
char *cptr;
long casize;
. . .
casize = 1024;
cptr = tpalloc("CARRAY", NULL, casize);
. . .
Upon success, the tpalloc() function returns a pointer of type char. For types other than STRING and CARRAY, you should cast the pointer to the proper C structure or FML pointer.
If the tpalloc() function encounters an error, it returns the NULL pointer. The following list provides examples of error conditions:
For a complete list of error codes and explanations of them, refer to tpalloc(3c) in the BEA Tuxedo ATMI C Function Reference.
The following listing shows how to allocate a STRING typed buffer. In this example, the associated default size is used as the value of the size argument to tpalloc().
char *cptr;
. . .
cptr = tpalloc("STRING", NULL, 0);
. . .
Once you have allocated a buffer, you can put data in it.
In the following example, a VIEW typed buffer called aud is created with three members (fields). The three members are b_id, the branch identifier taken from the command line (if provided); balance, used to return the requested balance; and ermsg, used to return a message to the status line for the user. When audit is used to request a specific branch balance, the value of the b_id member is set to the branch identifier to which the request is being sent, and the balance and ermsg members are set to zero and the NULL string, respectively.
...
audv = (struct aud *)tpalloc("VIEW", "aud", sizeof(struct aud));
/* Prepare aud structure */
audv->b_id = q_branchid;
audv->balance = 0.0;
(void)strcpy(audv->ermsg, "");
...
When audit is used to query the total bank balance, the total balance at each site is obtained by a call to the BAL server. To run a query on each site, a representative branch identifier is specified. Representative branch identifiers are stored in an array named sitelist[]. Hence, the aud structure is set up as shown in the following example.
...
/* Prepare aud structure */
audv->b_id = sitelist[i];/* routing done on this field */
audv->balance = 0.0;
(void)strcpy(audv->ermsg, "");
...
The process of putting data into a STRING buffer is illustrated in the listing titled Resizing a Buffer.
You can change the size of a buffer allocated with tpalloc() by using the tprealloc (3c) function as follows:
char*
tprealloc(char *ptr, long size)
The following table describes the arguments to the tprealloc() function.
Pointer to the buffer that is to be resized. This pointer must have been allocated originally by a call to
tpalloc(). If it was not, the call fails and tperrno(5) is set to TPEINVAL to signify that invalid arguments have been passed to the function.
|
|
The pointer returned by tprealloc() points to a buffer of the same type as the original buffer. You must use the returned pointer to reference the resized buffer because the location of the buffer may have changed.
When you call the tprealloc() function to increase the size of the buffer, the BEA Tuxedo system makes new space available to the buffer. When you call the tprealloc() function to make a buffer smaller, the system does not actually resize the buffer; instead, it renders the space beyond the specified size unusable. The actual content of the typed buffer remains unchanged. If you want to free up unused space, it is recommended that you copy the data into a buffer of the desired size and then
free the larger buffer.
On error, the tprealloc() function returns the NULL pointer and sets tperrno to an appropriate value. Refer to tpalloc
(3c) in BEA Tuxedo ATMI C Function Reference for information on error codes.
| WARNING: | If the tprealloc() function returns the NULL pointer, the contents of the buffer passed to it may have been altered and may be no longer valid. |
The following example shows how to reallocate space for a STRING buffer.
#include <stdio.h>
#include "atmi.h"
char instr[100]; /* string to capture stdin input strings */
long s1len, s2len; /* string 1 and string 2 lengths */
char *s1ptr, *s2ptr; /* string 1 and string 2 pointers */
main()
{
(void)gets(instr); /* get line from stdin */
s1len = (long)strlen(instr)+1; /* determine its length */
join application
if ((s1ptr = tpalloc("STRING", NULL, s1len)) == NULL) {
fprintf(stderr, "tpalloc failed for echo of: %s\n", instr);
leave application
exit(1);
}
(void)strcpy(s1ptr, instr);
make communication call with buffer pointed to by s1ptr
(void)gets(instr); /* get another line from stdin */
s2len = (long)strlen(instr)+1; /* determine its length */
if ((s2ptr = tprealloc(s1ptr, s2len)) == NULL) {
fprintf(stderr, "tprealloc failed for echo of: %s\n", instr);
free s1ptr's buffer
leave application
exit(1);
}
(void)strcpy(s2ptr, instr);
make communication call with buffer pointed to by s2ptr
. . .
}
The following example (an expanded version of the previous example) shows how to check for occurrences of all possible error codes.
. . .
if ((s2ptr=tprealloc(s1ptr, s2len)) == NULL)
switch(tperrno) {
case TPEINVAL:
fprintf(stderr, "given invalid arguments\n");
fprintf(stderr, "will do tpalloc instead\n");
tpfree(s1ptr);
if ((s2ptr=tpalloc("STRING", NULL, s2len)) == NULL) {
fprintf(stderr, "tpalloc failed for echo of: %s\n", instr);
leave application
exit(1);
}
break;
case TPEPROTO:
fprintf(stderr, "tried to tprealloc before tpinit;\n");
fprintf(stderr, "program error; contact product support\n");
leave application
exit(1);
case TPESYSTEM:
fprintf(stderr,
"BEA Tuxedo error occurred; consult today's userlog file\n");
leave application
exit(1);
case TPEOS:
fprintf(stderr, "Operating System error %d occurred\n",Uunixerr);
leave application
exit(1);
default:
fprintf(stderr,
"Error from tpalloc: %s\n", tpstrerror(tperrno));
break;
}
The tptypes
(3c) function returns the type and subtype (if one exists) of a buffer. The tptypes() function signature is as follows:
long
tptypes(char *ptr, char *type, char *subtype)
The following table describes the arguments to the tptypes() function.
Upon success, the tptypes() function returns the length of the buffer in the form of a long integer.
In the event of an error, tptypes() returns a value of -1 and sets tperrno(5) to the appropriate error code. For a list of these error codes, refer to the
Introduction to the C Language Application-to-Transaction Monitor Interface" and tpalloc(3c) in the BEA Tuxedo ATMI C Function Reference.
You can use the size value returned by tptypes() upon success to determine whether the default buffer size is large enough to hold your data, as shown in the following example.
. . .
iptr = (FBFR *)tpalloc("FML", NULL, 0);
ilen = tptypes(iptr, NULL, NULL);
. . .
if (ilen < mydatasize)
iptr=tprealloc(iptr, mydatasize);
The tpfree
(3c) function frees a buffer allocated by tpalloc() or reallocated by tprealloc(). The tpfree() function signature is as follows:
void
tpfree(char *ptr)
The tpfree() function takes only one argument, ptr, which is described in the following table.
Pointer to a data buffer. This pointer must have been allocated originally by a call to tpalloc() or tprealloc(), it may not be NULL, and it must be cast as a character type; otherwise, the function returns without freeing anything or reporting an error condition.
|
When freeing an FML32 buffer using tpfree(), the routine recursively frees all embedded buffers to prevent memory leaks. In order to preserve the embedded buffers, you should assign the associated pointer to NULL before issuing the tpfree() routine. When ptr is NULL, no action occurs.
The following example shows how to use the tpfree() function to free a buffer.
struct aud *audv; /* pointer to aud view structure */
. . .
audv = (struct aud *)tpalloc("VIEW", "aud", sizeof(struct aud));
. . .
tpfree((char *)audv);
There are two kinds of VIEW typed buffers. The first, FML VIEW, is a C structure generated from an FML buffer. The second is simply an independent C structure.
The reason for converting FML buffers into C structures and back again (and the purpose of the FML VIEW typed buffers) is that while FML buffers provide data-independence and convenience, they incur processing overhead because they must be manipulated using FML function calls. C structures, while not providing flexibility, offer the performance required for lengthy manipulations of buffer data. If you need to perform a significant amount of data manipulation, you can improve performance by transferring fielded buffer data to C structures, operating on the data using normal C functions, and then converting the data back to the FML buffer for storage or message transmission.
For more information on the FML typed buffer and FML file conversion, refer to the BEA Tuxedo ATMI FML Function Reference.
To use VIEW typed buffers, you must perform the following steps:
#include statement for your application program.
To use a VIEW typed buffer in an application, you must set the following environment variables.
To use a VIEW typed buffer, you must define the C record in a view description file. The view description file includes, a view for each entry, a view that describes the characteristic C structure mapping and the potential FML conversion pattern. The name of the view corresponds to the name of the C language structure.
The following format is used for each structure in the view description file:
$ /* View structure */
VIEW viewname
type cname fbname count flag size null
The following table describes the fields that must be specified in the view description file for each C structure.
|
|||
If you will be using the
FML-to-VIEW or VIEW-to-FML conversion functions, this field must be included to indicate the corresponding FML name. This field name must also appear in the FML
field table file. This field is not required for FML-independent VIEWs.
|
|||
|
|||
User-specified NULL value, or minus sign (
-) to indicate the default value for a field. NULL values are used in VIEW typed buffers to indicate empty C structure members.
The default NULL value for all numeric types is 0 (0.0 for
dec_t). For character types, the default NULL value is `\0'. For STRING, CARRAY, and MBSTRING types, the default NULL value is " ".
Constants used, by convention, as escape characters can also be used to specify a NULL value. The view compiler recognizes the following escape constants:
\ddd (where d is an octal digit), \0, \n, \t, \v, \r, \f, \\, \', and \".
You may enclose
STRING, CARRAY, MBSTRING, and char NULL values in double or single quotes. The view compiler does not accept unescaped quotes within a user-specified NULL value.
You can also specify the keyword NONE in the NULL field of a view member description, which means that there is no NULL value for the member. The maximum size of default values for string and character array members is 2660 characters. For more information, see BEA Tuxedo ATMI FML Function Reference.
|
You can include a comment line by prefixing it with the # or $ character. Lines prefixed by a $ sign are included in the .h file.
The following listing is an excerpt from an example view description file based on an FML buffer. In this case, the fbname field must be specified and match that which appears in the corresponding
field table file. Note that the CARRAY1 field includes an occurrence count of 2 and sets the C flag to indicate that an additional count element should be created. In addition, the L flag is set to establish a length element that indicates the number of characters with which the application populates the CARRAY1 field.
$ /* View structure */
VIEW MYVIEW
#type cname fbname count flag size null
float float1 FLOAT1 1 - - 0.0
double double1 DOUBLE1 1 - - 0.0
long long1 LONG1 1 - - 0
short short1 SHORT1 1 - - 0
int int1 INT1 1 - - 0
dec_t dec1 DEC1 1 - 9,16 0
char char1 CHAR1 1 - - '\0'
string string1 STRING1 1 - 20 '\0'
carray carray1 CARRAY1 2 CL 20 '\0'
END
The following listing illustrates the same view description file for an independent VIEW.
$ /* View data structure */
VIEW MYVIEW
#type cname fbname count flag size null
float float1 - 1 - - -
double double1 - 1 - - -
long long1 - 1 - - -
short short1 - 1 - - -
int int1 - 1 - - -
dec_t dec1 - 1 - 9,16 -
char char1 - 1 - - -
string string1 - 1 - 20 -
carray carray1 - 2 CL 20 -
END
Note that the format is similar to the FML-dependent view, except that the fbname and null fields are not relevant and are ignored by the viewc compiler. You must include a value (for example, a dash) as a placeholder in these fields.
To compile a VIEW typed buffer, run the viewc command, specifying the name of the view description file as an argument. To specify an independent VIEW, use the -n option. You can optionally specify a directory in which the resulting output file should be written. By default, the output file is written to the current directory.
For example, for an FML-dependent VIEW, the compiler is invoked as follows:
viewc myview.v
| Note: | To compile a VIEW32 typed buffer, run the viewc32 command. |
For an independent VIEW, use the -n option on the command line, as follows:
viewc -n myview.v
The output of the viewc command includes:
COPY files; for example, MYVIEW.cblmyview.V| Note: | On case-insensitive platforms (for example, Microsoft Windows), the extension used for the names of such files is vv; for example, myview.vv. |
The following listing provides an example of the header file created by viewc.
struct MYVIEW {
float float1;
double double1;
long long1;
short short1;
int int1;
dec_t dec1;
char char1;
char string1[20];
unsigned short L_carray1[2]; /* length array of carray1 */
short C_carray1; /* count of carray1 */
char carray1[2][20];
};The same header file is created for FML-dependent and independent VIEWs.
In order to use a VIEW typed buffer in client programs or service subroutines, you must specify the header file in the application #include statements.
To use FML typed buffers, you must perform the following steps:
FML header file and specify the header file in a #include statement in the application.
FML functions are used to manipulate typed buffers, including those that convert fielded buffers to C structures and vice versa. By using these functions, you can access and update data values without having to know how data is structured and stored. For more information on FML functions, see BEA Tuxedo ATMI FML Function Reference.
To use an FML typed buffer in an application program, you must set the following environment variables.
Field table files are always required when FML buffers and/or FML-dependent VIEWs are used. A field table file maps the logical name of a field in an FML buffer to a string that uniquely identifies the field.
The following format is used for the description of each field in the FML field table:
$ /* FML structure */
*basevaluename number type flags comments
The following table describes the fields that must be specified in the FML field table file for each FML field.
All fields are optional, and may be included more than once.
The following example illustrates a field table file that may be used with the FML-dependent VIEW example.
# name number type flags comments
FLOAT1 110 float - -
DOUBLE1 111 double - -
LONG1 112 long - -
SHORT1 113 short - -
INT1 114 long - -
DEC1 115 string - -
CHAR1 116 char - -
STRING1 117 string - -
CARRAY1 118 carray - -
In order to use an FML typed buffer in client programs or service subroutines, you must create an FML header file and specify it in the application #include statements.
To create an FML header file from a field table file, use the mkfldhdr(1) command. For example, to create a file called myview.flds.h, enter the following command:
mkfldhdr myview.flds
For FML32 typed buffers, use the mkfldhdr32 command.
The following listing shows the myview.flds.h header file that is created by the mkfldhdr command.
/* fname fldid */
/* ----- ----- */
#define FLOAT1 ((FLDID)24686) /* number: 110 type: float */
#define DOUBLE1 ((FLDID)32879) /* number: 111 type: double */
#define LONG1 ((FLDID)8304) /* number: 112 type: long */
#define SHORT1 ((FLDID)113) /* number: 113 type: short */
#define INT1 ((FLDID)8306) /* number: 114 type: long */
#define DEC1 ((FLDID)41075) /* number: 115 type: string */
#define CHAR1 ((FLDID)16500) /* number: 116 type: char */
#define STRING1 ((FLDID)41077) /* number: 117 type: string */
#define CARRAY1 ((FLDID)49270) /* number: 118 type: carray */
Specify the new header file in the #include statement of your application. Once the header file is included, you can refer to fields by their symbolic names.
As XML continues to gain acceptance as a data standard, BEA Tuxedo customers are increasingly using XML typed buffers in their applications. To assist customers in this effort, BEA has integrated the Apache Xerces C++ Version 2.5 parser into the BEA Tuxedo software distribution.
This section introduces the following topics:
XML buffers enable BEA Tuxedo applications to use XML for exchanging data within and between applications. BEA Tuxedo applications can send and receive simple XML buffers, and route those buffers to the appropriate servers. All logic for dealing with XML documents, including parsing, resides in the application.
The programming model for the XML buffer type is similar to that for the CARRAY buffer type: you must specify the length of the buffer with the tpalloc() function. The maximum supported size of an XML document is 4 GB.
Formatting and filtering for Events processing (which are supported when a STRING buffer type is used) are not supported for the XML buffer type. Therefore, the _tmfilter and _tmformat function pointers in the buffer type switch for XML buffers are set to NULL.
The XML parser in the BEA Tuxedo system performs the following functions:
Data-dependent routing is supported for XML buffers. The routing of an XML document can be based on element content, or on element type and an attribute value. The XML parser determines the character encoding being used; if the encoding differs from the native character sets (US-ASCII or EBCDIC) used in the BEA Tuxedo configuration files (UBBCONFIG and DMCONFIG), the element and attribute names are converted to US-ASCII or EBCDIC.
Attributes configured for routing must be included in an XML document. If an attribute is configured as a routing criteria but it is not included in the XML document, routing processing fails.
The content of an element and the value of an attribute must conform to the syntax and semantics required for a routing field value. The user must also specify the type of the routing field value. XML supports only character data. If a range field is numeric, the content or value of that field is converted to a numeric value during routing processing.
The Xerces-C++ 2.5.0 parser, written in a portable subset of C++, comes with a shared library for parsing, generating, manipulating, and validating XML documents. It complies with the XML 1.0 recommendation and associated standards DOM 1.0, DOM 2.0. SAX 1.0, SAX 2.0, Namespaces, and W3C's XML Schema recommendation version 1.0.
Because the Xerces-C++ 1.7 parser did not cache the Document Type Definition (DTD) and XML Schema files when validation was required, or cache external entity files used in DTD, BEA Tuxedo 8.1 improved the performance of the Xerces-C++ 1.7 parser by adding an option to cache external DTD, Schema, and entity files that might otherwise be retrieved repeatedly over the Web. Continued support for this modification is available with Tuxedo 9.x and Xerces C++ 2.5.0.
There are two ways to turn on/off caching for the Xerces-C++ parser:
| Note: | These four methods are bea Tuxedo enhancements to the Apache Xerces-C++ parser. They are used exclusively in conjunction with the following two Xerces objects : |
The International Components for Unicode (ICU) 3.0 library, a C/C++ library that supports over 200 different coded character sets (encoding forms) on a wide variety of platforms, is included with the BEA Tuxedo distribution. The Xerces-C++ 2.5.0 parser is built with the ICU 3.0 library.
A sample application for using the Xerces-C++ parser ATMI functions is provided in the BEA Tuxedo user documentation. Among other things, the sample demonstrates how to write a wrapper for the Xerces-C++ parser so that Tuxedo clients and servers written in C can call the Xerces-C++ ATMI functions.
A sample application for using XML schemas with the Xerces parser is provided in the BEA Tuxedo documentation. See Tutorial for xmlfmlapp: A Full C XML/FML32 Conversion Application in Tutorials for Developing BEA Tuxedo ATMI Applications
getURLEntityCacheDir(3c), setURLEntityCacheDir(3c), getURLEntityCaching(3c), setURLEntityCaching(3c), Xerces API parser on-line documentation.
As an input/output format, XML data is gaining broader use in modern application development. Most Tuxedo customers, in contrast, have large investments in existing defined services that make use of Tuxedo FML/FML32 buffers as the preferred data transport.
BEA Tuxedo addresses this issue by adding functionality that allows for data conversion of XML to and from FML/FML32 buffers. This conversion can be initiated one of two ways:
For programmers, on-demand conversion of XML data to and from FML/FML32 buffers features four new ATMI functions for manual conversion. For more information, see Using On-Demand Conversion.
For application administrators, automatic conversion of XML to and from FML/FML32 buffers features a new BUFTYPECONV parameter in the SERVICES section of the UBBCONFIG configuration file initiates conversion when the server is booted. For more information, see Using Automatic Conversion.
Regardless of the method used for conversion, the FML/FML32 field types are mapped to XML in a particular manner. For information on conversion mapping, see Mapping XML To and From FML/FML32 Field Types.
| Note: | XML to and from FML/FML32 conversion uses third-party libraries (for example, libticudata.so) that may be substantial in size. |
| Note: | Increasing the size of shared libraries may cause running Tuxedo application processes (that directly or indirectly depend on those libraries) to consume increased amounts of memory which, in turn, can impact performance. |
| Note: | XML to and from FML/FML32 conversion should not be used by a Tuxedo system process. |
| Note: | For other known issues or limitations regarding conversion between XML and FML/FML32 buffers using the Xerces parser, see Conversion Limitations. |
On-demand conversion gives you the option to manually execute conversion of XML data to FML/FML32 buffers or conversion of FML/FML32 buffers to XML.
The following four ATMI functions provide on-demand conversion:
For a detailed description of these functions and their arguments, see "BEA Tuxedo ATMI C Function Reference."
For on-demand conversion of XML data to and from FML/FML32 buffers, perform the following steps:
If you are using the ATMI functions to initiate conversion of XML to and from FML/FML32 buffers, parser validation is determined one of two ways.
For a detailed description of the ATMI functions and their Xerces parser flag arguments, see BEA Tuxedo ATMI C Function Reference."
Automatic conversion starts and ends with XML. That is, XML buffers are input, converted and processed to FML/FML32 buffers, and finally reconverted back to XML.
To initiate conversion between XML and FML/FML32 buffers you must specify the BUFTYPECONV parameter in the SERVICES section of the UBBCONFIG file. This parameter accepts only one of two value options: XML2FML or XML2FML32.
When you boot a server with this parameter, the input buffer is converted from an XML buffer to an FML/FML32 buffer via client tpcall(), tpacall(), tpconnect(), or tpsend()before being delivered to the service. When tpreturn() or tpsend() is called, an FML/FML32 buffer is converted to XML before it is returned.
Services using the BUFTYPECONV parameter allow clients or other services to send and receive XML buffers without changing how the existing service handles FML/FML32 buffers.
| Note: | Keep in mind the following regarding BUFTYPECONV parameter use: |
BUFTYPECONV parameter, all output FML/FML32 buffers are converted to XML. Creating a new service name using the BUFTYPECONV parameter allows you to output XML and keep the original service name to output FML/FML32 buffers.BUFTYPECONV.server. In other words, if a client or other service makes a request to the service using the BUFTYPECONV parameter. BUFTYPECONV parameter acts as a client, conversion does not take place. For example, a service with the BUFTYPECONV parameter using tpcall() on another service./Q messaging mode, TMQFORWARD uses tpcall() to call a service. If the called service uses the BUFTYPECONV parameter, automatic conversion will take place.
During automatic conversion, the input XML root element name cannot be saved, so the output XML root tag
uses the default root tag <FML Type="FML"> or <FML Type="FML32">.
For automatic conversion of XML data to and from FML/FML32 buffers, perform the following steps:
The Xerces parser uses default attribute settings to control XML validation during automatic conversion. However, Tuxedo supports 14 specific Xerces DOMParser class attributes that provide some automatic conversion customizing flexibility.
If you are using the automatic conversion method, parser validation is determined one of two ways:
TPXPARSFILE environment variable
The TPXPARSFILE environment variable designates the fully qualified path to a text file that contains the XercesDOMParser class attribute settings you want to modify.
Each attribute in the text file is written on a separate line in the following format:
<parser attribute>=<setting>
The <parser attribute> can be any or all of the 14 parser attributes in the following table, where (D) denotes the default setting.
| Note: | For a detailed description of these attributes, see Xerces parser 2.5.0 documentation. |
The following listing is a sample input plain text file for the TPXPARSFILE environment variable.
CacheGrammarFromParse=True
DoNameSpaces=True
DoSchema=True
ExternalSchemaLocation= http://www.xml.org/sch.xsd
ExitOnFirstFatalError=c:\xml\example.xsd
IncludeIgnorableWhiteSpace=True
LoadGrammar=
NoNamespaceSchemaLocation=
StandardUriConformant=True
UseCachedGrammarInParse=True
UseScanner=WF
ValidationConstraintFatal=True
ValidationScheme=Val_Auto
ValidationSchemaFullChecking=True
The relationship between the XML format and the FML/FML32 fields is one in which the XML element names are the same as the FML/FML32 field names, and the XML values are interpreted using the corresponding field type.
The opening and closing tag uses the name of the field. Attributes are optionally provided for FLD_FML32, FLD_MBSTRING and FLD_VIEW32. Field names and attributes are case sensitive.
The field value is read as a string and converted to the following field type:
<FIELDNAME Attribute="Attribute Value"> FIELDVALUE </FIELDNAME>
FML/FML32 field types are mapped to XML buffer types as follows:
During conversion to XML, the
During conversion to FML32, the |
||||
The
FLD_FML32 fieldname is supported with the opening and closing tags based upon the FML field name. This XML document includes multiple descriptions of <fieldname>value</fieldname> for each field contained in the buffer.
|
||||
The
FLD_VIEW32 fieldname is supported, and therefore, the FLD_INT and FLD_DECIMAL fields are also recognized. FLD_INT is treated like FLD_LONG.
|
||||
The
FLD_MBSTRING field conversion uses the Encoding attribute and the field data to describe the FML32 field. This conversion is similar to Fmbpack32 usage. Please note the following conditions:
|
The following limitations exist for conversion of XML data to and from FML/FML32 buffers using the Xerces 2.5.0 parser delivered with Tuxedo.
<FML Type="FML"> or <FML Type="FML32"> is used.
To support the multibyte coded character sets required by Chinese, Japanese, Korean, and other Asian Pacific languages, BEA Tuxedo includes the MBSTRING typed buffer for transport of multibyte character user data. Chinese, Japanese, Korean, and other Asian Pacific languages use coded character sets that use more than one byte to represent a character.
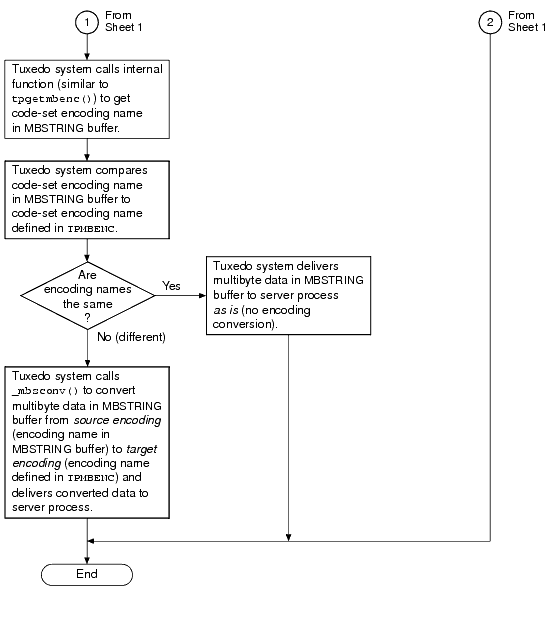
Using the MBSTRING typed buffer and the multibyte character encoding feature, the BEA Tuxedo system can convert user data from one encoding representation to another encoding representation when an MBSTRING buffer (or an FLD_MBSTRING field in an FML32 buffer) is transmitted between processes. The following figure shows through example how encoding conversion works.
As indicated in the example, the MBSTRING typed buffer is capable of carrying information identifying the code-set character encoding, or simply encoding, of its user data. In the example, the client-request MBSTRING buffer holds Japanese user data represented by the Shift-JIS (SJIS) encoding, while the server-reply MBSTRING buffer holds Japanese user data represented by the Extended UNIX Code (EUC) encoding. The multibyte character encoding feature reads environment variables TPMBENC and TPMBACONV to determine the source encoding, the target encoding, and the state (on or off) of automatic encoding conversion.
The encoding conversion capability enables the underlying Tuxedo system software to convert the encoding representation of an incoming message to an encoding representation supported by the machine on which the receiving process is running. The conversion is neither a conversion between character code sets nor a translation between languages, but rather a conversion between different character encodings for the same language.
There are two ways of controlling character encoding conversions:
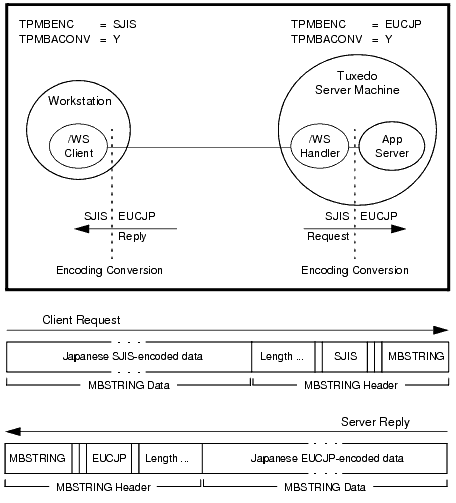
The following two flowcharts demonstrate how the environment variables and ATMI are used during the allocating, sending, receiving, and converting of an MBSTRING buffer.
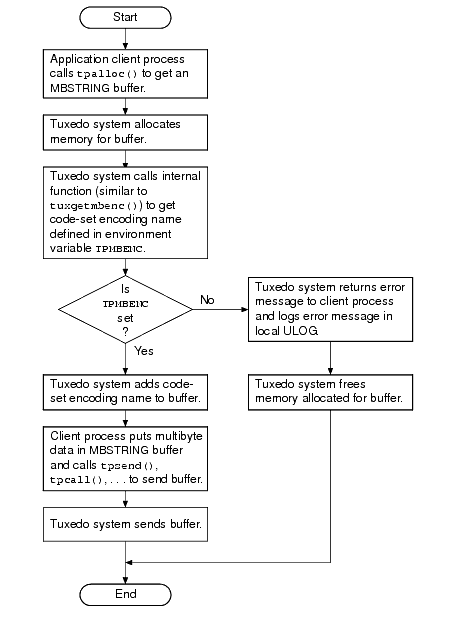
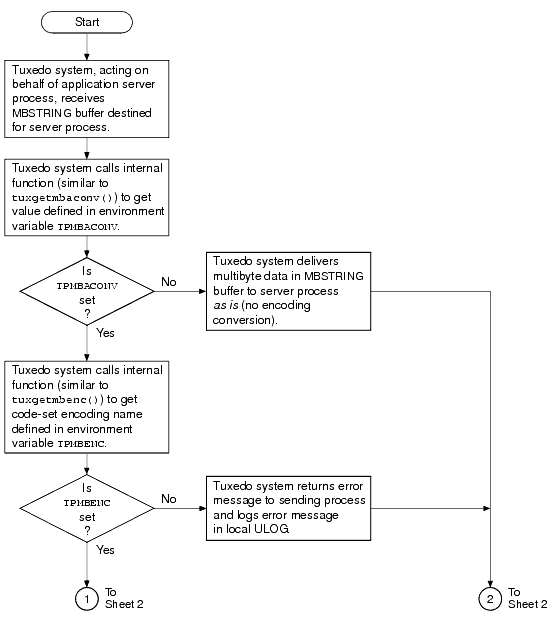
MBSTRING can be self-describing if sendlen is set to zero. Some Tuxedo buffers provide a capability for the buffer to determine its own length if the user does not provide it. This self-describing behavior is triggered when an application sets the sendlen argument of a Tuxedo function call (for example, tpcall()) to zero.
This self-describing behavior is implemented by adding the following:
The _mbspresend() addition requires any user who customizes Tuxedo buffers to rebuild their applications.
The idea of safe or unsafe encoding names specified by TPMBENC comes from whether or not the multibyte character data for these encodings can contain embedded NULLs. Because the _mbspresend() function uses strlen() to determine the length of the data, an embedded NULL causes the length to be incorrectly set and the wrong number of data bytes are sent.
The default list in sendlen0_unsafe_tpmbenc has the multibyte Unicode encoding names (in uppercase and lowercase, for convenience) which can contain embedded NULLs. You should modify this list as application administration or performance is considered.
MBSTRING self-describing attempts.MBSTRING self-describing attempts (tperrno will be TPEINVAL)._mbsinit()) and stores the list internally. During mbsinit(), the TPMBENC name is compared to the stored list and the buffer is set as safe or unsafe to use. When _mbspresend() is called (sendlen argument is set to zero) and the buffer is marked safe, then the length is set internally by Tuxedo.The following limitations exist for the multibyte character support in BEA Tuxedo:
MBSTRING and FLD_MBSTRING.
libiconv, an encoding conversion library that provides support for many coded character sets and encodings, is included with the BEA Tuxedo 8.1 or later software distribution. The multibyte character encoding feature uses the character conversion functions in this library to convert from any of the supported character encodings to any other supported character encoding, through Unicode conversion.
libiconv provides support for the following encodings:
For more information about multibyte character encoding, see the following documents:
You may find that the buffer types supplied by the BEA Tuxedo system do not meet your needs. For example, perhaps your application uses a data structure that is not flat, but has pointers to other data structures, such as a parse tree for an SQL database query. To accommodate unique application requirements, the BEA Tuxedo system supports customized buffers.
To customize a buffer, you need to identify the following characteristics.
Name of the buffer subtype, specified by a string of up to 16 characters. The system uses a subtype to identify different processing requirements for buffers of a given type. When the wildcard character (*) is specified as the subtype value, all buffers of a given type can be processed using the same generic routine. Any buffers for which a subtype is defined must appear before the wildcard in the list, in order to be processed correctly.
|
|
The following table defines the list of routines that you may need to specify for each buffer type. If a particular routine is not applicable, you can simply provide a NULL pointer; the BEA Tuxedo system uses default processing, as necessary.
Performs all the encoding and decoding necessary for the buffer type. A request to encode or decode is passed to the routine, along with input and output buffers and lengths. The format used for encoding is determined by the application and, as with the other routines, it may be dependent on the buffer type.
|
|
Specifies the routing information. This routine is called with a typed buffer, the length of the data for that buffer, a logical routing name configured by an administrator, and a target service. Based on this information, the application must select the server group to which the message should be sent or indicate that the message is not needed.
|
|
The application programmer is responsible for the code that manipulates buffers, which allocates and frees space, and sends and receives messages. For applications in which the default buffer types do not meet the needs of the application, other buffer types can be defined, and new routines can be written and then incorporated into the buffer type switch.
To define other buffer types, complete the following steps:
tm_typesw.
If your application is using static libraries and you are providing a customized buffer type switch, then you must build a custom server to link in your new type switch. For details, see buildwsh (1), TMQUEUE (5), or TMQFORWARD (5).
The rest of the sections in this topic address the steps listed in the preceding procedure to define a new buffer type in a shared-object or DLL environment. First, however, let's look at the buffer switch that is delivered with the BEA Tuxedo system software. The following listing shows the switch delivered with the system.
#include <stdio.h>
#include <tmtypes.h>
/*
* Initialization of the buffer type switch.
*/
struct tmtype_sw_t tm_typesw[] = {
{
"CARRAY", /* type */
"*", /* subtype */
0 /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
NULL, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
NULL, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"STRING", /* type */
"*", /* subtype */
512, /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
_strpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_strencdec, /* encdec */
NULL, /* route */
_sfilter, /* filter */
_sformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"FML", /* type */
"*", /* subtype */
1024, /* dfltsize */
_finit, /* initbuf */
_freinit, /* reinitbuf */
_funinit, /* uninitbuf */
_fpresend, /* presend */
_fpostsend, /* postsend */
_fpostrecv, /* postrecv */
_fencdec, /* encdec */
_froute, /* route */
_ffilter, /* filter */
_fformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"VIEW", /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
/* XATMI - identical to CARRAY */
"X_OCTET", /* type */
"*", /* subtype */
0 /* dfltsize */
},
{ /* XATMI - identical to VIEW */
{'X','_','C','_','T','Y','P','E'}, /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
/* XATMI - identical to VIEW */
{'X','_','C','O','M','M','O','N'}, /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit, /* initbuf */
_vreinit, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec, /* encdec */
_vroute, /* route */
_vfilter, /* filter */
_vformat, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"FML32", /* type */
"*", /* subtype */
1024, /* dfltsize */
_finit32, /* initbuf */
_freinit32, /* reinitbuf */
_funinit32, /* uninitbuf */
_fpresend32, /* presend */
_fpostsend32, /* postsend */
_fpostrecv32, /* postrecv */
_fencdec32, /* encdec */
_froute32, /* route */
_ffilter32, /* filter */
_fformat32, /* format */
_fpresend232, /* presend2 */
_fmbconv32 /* multibyte code-set encoding conversion */
},
{
"VIEW32", /* type */
"*", /* subtype */
1024, /* dfltsize */
_vinit32, /* initbuf */
_vreinit32, /* reinitbuf */
NULL, /* uninitbuf */
_vpresend32, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
_vencdec32, /* encdec */
_vroute32, /* route */
_vfilter32, /* filter */
_vformat32, /* format */
NULL, /* presend2 */
_vmbconv32, /* multibyte code-set encoding conversion */
},
{
"XML", /* type */
"*", /* subtype */
0, /* dfltsize */
NULL, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
NULL, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
_xroute, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
NULL /* multibyte code-set encoding conversion */
},
{
"MBSTRING", /* type */
"*", /* subtype */
0, /* dfltsize */
_mbsinit, /* initbuf */
NULL, /* reinitbuf */
NULL, /* uninitbuf */
_mbspresend, /* presend */
NULL, /* postsend */
NULL, /* postrecv */
NULL, /* encdec */
NULL, /* route */
NULL, /* filter */
NULL, /* format */
NULL, /* presend2 */
_mbsconv /* multibyte code-set encoding conversion */
},
{
""
}
};struct tmtype_sw_t _TM_FAR *
_TMDLLENTRY
_tmtypeswaddr(void)
{
return(tm_typesw);
}
For a better understanding of the preceding listing, consider the declaration of the buffer type structure that is shown in the following listing.
/*
* The following definitions are in $TUXDIR/include/tmtypes.h
*/
#define TMTYPELEN ED_TYPELEN
#define TMSTYPELEN ED_STYPELEN
struct tmtype_sw_t {
char type[TMTYPELEN]; /* type of buffer */
char subtype[TMSTYPELEN]; /* subtype of buffer */
long dfltsize; /* default size of buffer */
/* buffer initialization function pointer */
int (_TMDLLENTRY *initbuf) _((char _TM_FAR *, long));/* buffer reinitialization function pointer */
int (_TMDLLENTRY *reinitbuf) _((char _TM_FAR *, long));
/* buffer un-initialization function pointer */
int (_TMDLLENTRY *uninitbuf) _((char _TM_FAR *, long));
/* pre-send buffer manipulation func pointer */
long (_TMDLLENTRY *presend) _((char _TM_FAR *, long, long));
/* post-send buffer manipulation func pointer */
void (_TMDLLENTRY *postsend) _((char _TM_FAR *, long, long));
/* post-receive buffer manipulation func pointer*/
long (_TMDLLENTRY *postrecv) _((char _TM_FAR *, long, long));
/* XDR encode/decode function pointer */
long (_TMDLLENTRY *encdec) _((int, char _TM_FAR *, long, char _TM_FAR *, long));
/* routing function pointer */
int (_TMDLLENTRY *route) _((char _TM_FAR *, char _TM_FAR *, char _TM_FAR *,
long, char _TM_FAR *));
/* buffer filtering function pointer */
int (_TMDLLENTRY *filter) _((char _TM_FAR *, long, char _TM_FAR *, long));
/* buffer formatting function pointer */
int (_TMDLLENTRY *format) _((char _TM_FAR *, long, char _TM_FAR *,
char _TM_FAR *, long));
/* process buffer before sending, possibly generating copy */
long (_TMDLLENTRY *presend2) _((char _TM_FAR *, long,
long, char _TM_FAR *, long, long _TM_FAR *));
/* Multibyte code-set encoding conversion function pointer*/
long (_TMDLLENTRY *mbconv) _((char _TM_FAR *, long,
char _TM_FAR *, char _TM_FAR *, long, long _TM_FAR *));
/* this space reserved for future expansion */
void (_TMDLLENTRY *reserved[8]) _((void));
};
/*
* application types switch pointer
* always use this pointer when accessing the table
*/
extern struct tmtype_sw_t *tm_typeswp;
The listing for the default buffer type switch shows the initialization of the buffer type switch. The nine default buffer types are shown, followed by a field for naming a subtype. Except for the VIEW (and equivalently X_C_TYPE and X_COMMON) type, subtype is NULL. The subtype for VIEW is given as ``*'', which means that the default VIEW type puts no constraints on subtypes; all subtypes of type VIEW are processed in the same manner.
The next field gives the default (minimum) size of the buffer. For the CARRAY (and equivalently X_OCTET) type this is given as 0, which means that the routine that uses a CARRAY buffer type must tpalloc() enough space for the expected CARRAY.
For the other types, the BEA Tuxedo system allocates (with a tpalloc() call) the space shown in the dfltsize field of the entry (unless the size argument of tpalloc() specifies a larger size).
The remaining eight fields of entries in the buffer type switch contain the names of switch element routines. These routines are described in the buffer(3c) page in the BEA Tuxedo C Function Reference. The name of a routine provides a clue to the purpose of the routine. For example, _fpresend on the FML type is a pointer to a routine that manipulates the buffer before sending it. If no presend manipulation is needed, a NULL pointer may be specified. NULL means no special handling is required; the default action should be taken. See buffer(3c) for details.
It is particularly important that you notice the NULL entry at the end of the switch. Any changes that are made must always leave the NULL entry at the end of the array.
Presumably an application that is defining new buffer types is doing so because of a special processing need. For example, let's assume the application has a recurring need to compress data before sending a buffer to the next process. The application could write a presend routine. The declaration for the presend routine is shown in the following listing.
long
presend(ptr, dlen, mdlen)
char *ptr;
long dlen, mdlen;
The data compression that takes place within your presend routine is the responsibility of the system programmer for your application.
On completion the routine should return the new, hopefully shorter length of the data to be sent (in the same buffer), or a -1 to indicate failure.
The name given to your version of the presend routine can be any identifier accepted by the C compiler. For example, suppose we name it _mypresend.
If you use our _mypresend compression routine, you will probably also need a corresponding _mypostrecv routine to decompress the data at the receiving end. Follow the template shown in the buffer(3c) entry in the BEA Tuxedo C Function Reference.
After the new switch element routines have been written and successfully compiled, the new buffer type must be added to the buffer type switch. To do this task, we recommend making a copy of $TUXDIR/lib/tmtypesw.c (the source code for the default buffer type switch). Give your copy a name with a .c suffix, such as mytypesw.c. Add the new type to your copy. The name of the type can be up to 8 characters in length. Subtype can be null ("") or a string of up to 16 characters. Enter the names of your new switch element routines in the appropriate locations, including the extern declarations. The following listing provides an example.
#include <stdio.h>
#include <tmtypes.h>
/* Customized the buffer type switch */
static struct tmtype_sw_t tm_typesw[] = {
{
"SOUND", /* type */
"", /* subtype */
50000, /* dfltsize */
snd_init, /* initbuf */
snd_init, /* reinitbuf */
NULL, /* uninitbuf */
snd_cmprs, /* presend */
snd_uncmprs, /* postsend */
snd_uncmprs /* postrecv */
},
{
"FML", /* type */
"", /* subtype */
1024, /* dfltsize */
_finit, /* initbuf */
_freinit, /* reinitbuf */
_funinit, /* uninitbuf */
_fpresend, /* presend */
_fpostsend, /* postsend */
_fpostrecv, /* postrecv */
_fencdec, /* encdec */
_froute, /* route */
_ffilter, /* filter */
_fformat /* format */
},
{
""
}
};
In the previous listing, we added a new type: SOUND. We also removed the entries for VIEW, X_OCTET, X_COMMON, and X_C_TYPE, to demonstrate that you can remove any entries that are not needed in the default switch. Note that the array still ends with the NULL entry.
An alternative to defining a new buffer type is to redefine an existing type. Suppose, for the sake of argument, that the data compression for which you defined the buffer type MYTYPE was performed on strings. You could substitute your new switch element routines, _mypresend and _mypostrecv, for the two _dfltblen routines in type STRING.
To simplify installation, the buffer type switch is stored in a shared object.
| Note: | On some platforms the term "shared library" is used instead of "shared object." On the Windows 2003 platform a "dynamic link library" is used instead of a "shared object." For the purposes of this discussion, however, the functionality implied by all three terms is equivalent, so we use only one term. |
This section describes how to make all BEA Tuxedo processes in your application aware of the modified buffer type switch. These processes include application servers and clients, as well as servers and utilities provided by the BEA Tuxedo system.
$TUXDIR/lib/tmtypesw.c, as described in Adding a New Buffer Type to tm_typesw. If additional functions are required, store them in either tmtypesw.c or a separate C source file.tmtypesw.c with the flags required for shared objects.libbuft.so.71 from the current directory to a directory in which it will be visible to applications, and processed before the default shared object supplied by the BEA Tuxedo system. We recommend using one of the following directories: $APPDIR, $TUXDIR/lib, or $TUXDIR/bin (on a Windows 2003 platform).Different platforms assign different names to the buffer type switch shared object, to conform to operating system conventions.
Please refer to the software development documentation for your platform for instructions on building a shared object library.
As an alternative, it is possible to statically link a new buffer type switch in every client and server process, but doing so is more error-prone and not as efficient as building a shared object library.
If you have modified tmtypesw.c on a Windows platform, as described in Compiling and Linking Your New tm_typesw, then you can use the commands shown in the following sample code listing to make the modified buffer type switch available to your application.
CL -AL -I..\e\|sysinclu -I..\e\|include -Aw -G2swx -Zp -D_TM_WIN
-D_TMDLL -Od -c TMTYPESW.C
LINK /CO /ALIGN:16 TMTYPESW.OBJ, WBUFT.DLL, NUL, WTUXWS /SE:250 /NOD
/NOE LIBW LDLLCEW, WBUFT.DEF
RC /30 /T /K WBUFT.DLL
The purpose of the TYPE parameter in the MACHINES section of the configuration file is to group together machines that have the same form of data representation (and use the same compiler) so that data conversion is done on messages going between machines of different TYPEs. For the default buffer types, data conversion between unlike machines is transparent to the user (and to the administrator and programmer, for that matter).
If your application defines new buffer types for messages that move between machines with different data representation schemes, you must also write new encode/decode routines to be incorporated into the buffer type switch. When writing your own data conversion routines, keep the following guidelines in mind:
_tmencdec routine shown on reference page buffer(3c) in BEA Tuxedo ATMI C Function Reference; that is, you should code your routine so that it uses the same arguments and returns the same values on success or failure as the _tmencdec routine. When defining new buffer types, follow the procedure provided in Defining Your Own Buffer Types for building servers with services that will use your new buffer type.
The encode/decode routines are called only when the BEA Tuxedo system determines that data is being sent between two machines that are not of the same TYPE.


|